作者:小傅哥
博客:https://bugstack.cn
原文:https://mp.weixin.qq.com/s/t_ExuckR6Pd-H1Pa21HFyg
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
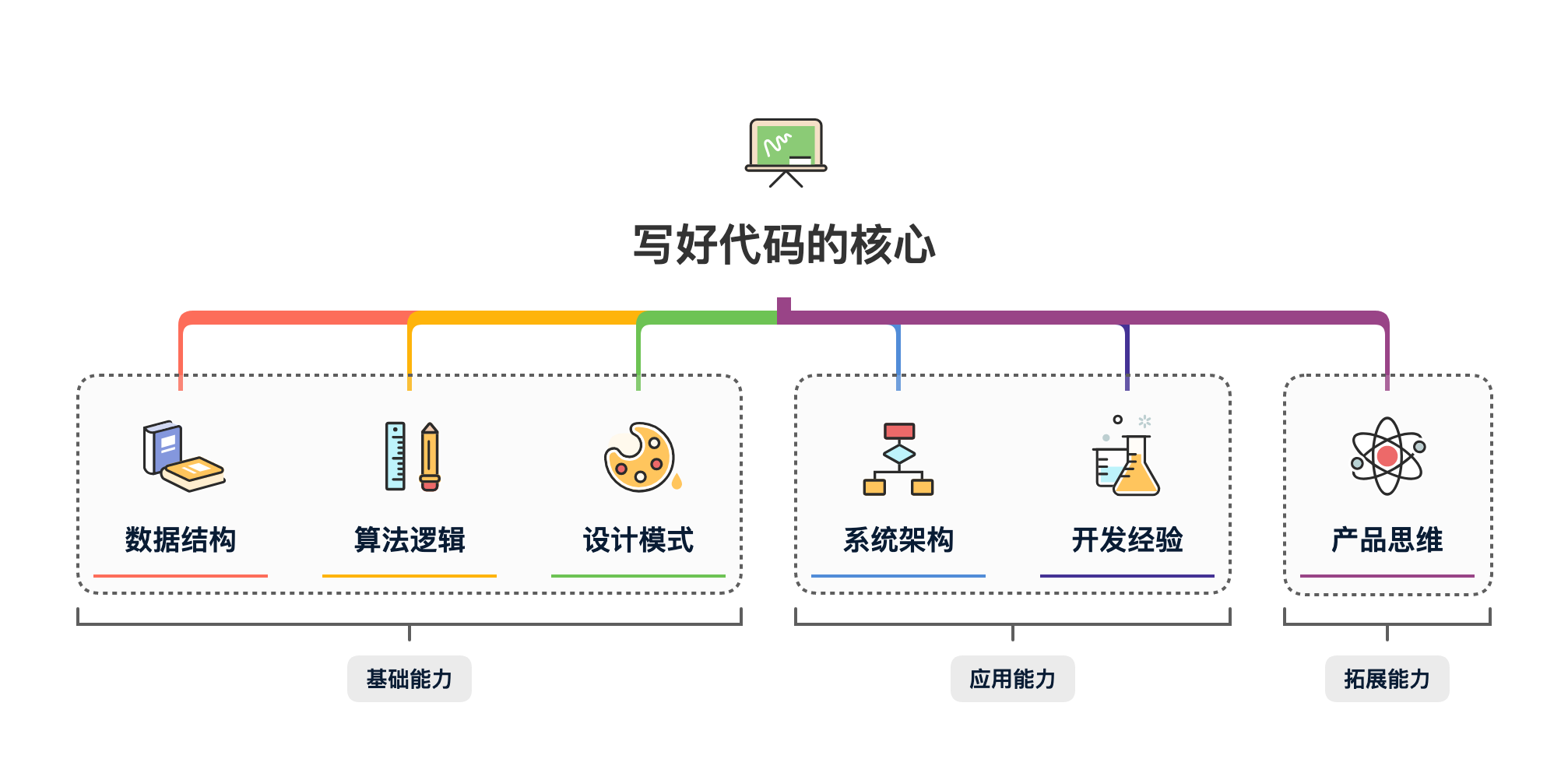
为什么你的代码一坨坨?其实来自你有那么多为什么你要这样写代码!
- 为什么你的代码那么多for循环?因为没有合理的数据结构和算法逻辑。
- 为什么你的代码那么多ifelse?因为缺少设计模式对业务场景的运用。
- 为什么你的程序应用复杂对接困难?因为没有良好的系统架构拆分和规划。
- 为什么你的程序逻辑开发交付慢返工多?因为不具备某些业务场景的开发经验。
- 为什么你的程序展现都是看上去不说人话?因为没有产品思维都是程序员逻辑的体现。
最终,所有的这些不合理交织在一起,就是你能看到的一坨坨的代码!所以,要想把代码写好、写美,写到自己愿意反复欣赏,那么基本需要你有一定的:基础能力(数据结构、算法逻辑、设计模式)、应用能力(系统架构、开发经验)、拓展能力(产品思维),这三方面综合起来才能更好的开发程序。
但可能杠精会喊,我就写个CRUD要什么逻辑、什么数据结构,还算法? 但写CRUD并不一定业务需求是CRUD,只是你的知识面和技术深度只能把它设计成CRUD,用ifelse和for循环在一个类里反复粘贴复制罢了。
可能同样的需求交给别人手里,就会想的更多搭建的更加完善。就像:树上10只鸟开一枪还剩下几只,你会想到什么?比如:
- 手抢是无声的吗?
- 枪声大吗?
- 这个城市打鸟犯不犯法?
- 确定那只鸟被打死了?
- 树上的鸟有没有聋子?
- 有没有被关在笼子里或者绑在树上的鸟?
- 旁边还有其他树吗?
- 有残疾或者飞不动的鸟吗?
- 有怀孕肚子里的鸟吗?
- 打鸟的人眼睛花没花?
- 保证是10只吗?
- 有没有那种不怕死的鸟?
- 会不会一枪打死两只或者更多?
- 所有的鸟都可以自由活动飞离树以外吗?
- 打死以后挂在树上还是掉下来了?
所以,你还相信写程序只是简简单单的搞CRUD吗?接下来小傅哥再带着你搞几个例子看一看!
二、代码就是对数学逻辑的具体实现
数据结构:数组、链表、红黑树 算法逻辑:哈希、扰动函数、负载因子、拉链寻址、
其实我们所开发的业务程序,哪怕是CRUD也都是对数学逻辑的具体实现过程。只不过简单的业务有简单的数学逻辑、复杂的业务有复杂的数学逻辑。数学逻辑是对数据结构的使用,(例如:把大象装进冰箱分几步)合理的数据的结构有利于数据逻辑的实现和复杂程度。
在我们常用的API中,HashMap 就是一个非常好的例子,既有非常好的数据结构的使用,也有强大的数学逻辑的实现。为此也让 HashMap 成为开发过程中非常常用的API,当然也成为面试过程中最常问的技术点。

重点,HashMap 中涉及的知识点非常多,包括数据结构的使用、数组、链表、红黑树,也包括算法逻辑的实现:哈希、扰动函数、负载因子、拉链寻址等等。而这些知识如果可以深入的搞清楚,是完全不需要死记硬背的,也不需要为了面试造火箭。就像如下问题:
- HashMap 怎么来的?因为有非常多业务开发中需要key、value的形式存放获取数据。
- 为什么要用哈希计算下标呢?因为哈希值求计算出的 key 具有低碰撞性。
- 为什么还要加扰动函数呀?因为扰动函数可以让数据散列的均匀,如果HashMap中的数据都碰撞成短链表,就会大大降低HashMap的索引性能。
- 为什么会有链表呢?因为无论如何都有会有节点碰撞的可能,碰撞后HashMap选择拉链寻址的方式存放数据。当然在 ThreadLocal 中采用的是斐波那契(Fibonacci)散列+开放寻址,感兴趣也可以看看。
- 为什么链表会转换树呢?因为时间复杂度问题,链表的时间复杂度是O(n),越长越慢。
- 为什么树是红黑树呢?红黑树具有平衡性,也就是黑色节点是平衡的,平衡带来的效果就是控制整体树高,让时间复杂度最终保持在O(logn),否则都是一丿的树就没意义了。
- 为什么有个负载因子呢?负载因子决定HashMap的高矮胖瘦,负载你可以理解成一辆卡车能装多少货,装的越多这一趟赚的也阅读风险也越高,装的越少跑的越快赚的也少。所以选择了适当大小0.75。
- 为什么JDK8优化了数据扩容时迁移?那不就是因为计算哈希值求下标耗费时间吗,已经找到了数学规律,直接迁移就可以了,提高性能。
看到了吗? HashMap完全就是对数据结构的综合使用,以及对数学逻辑的完美结合,才让我们有了非常好用的HashMap。这些知识的学习就可以技术迁移到我们自己业务开发中,把有些业务开发优化到非常不错的性能体现上。同时你的代码也值得加薪!
哈希下标
图 15-2 中涉及到的下标位置存放的数据,不是胡乱写的。是按照 HashMap 中的计算逻辑找到的固定位置值。代码如下:
for (int i = 1; i < 1000; i++) {
String key = String.valueOf(i);
int hash = key.hashCode() ^ (key.hashCode() >>> 16);
int idx = (64 - 1) & hash;
if (idx == 2) {
// System.out.println(i + " Idx:" + idx);
}
if (idx == 62) {
System.out.println(i + " Idx:" + idx);
}
}
如果你需要英文的,那么可以跑10万单词的字典表。关于HashMap的内容小傅哥已经整理到面经手册中,链接:面经手册 • 拿大厂Offer
三、得物(毒) 8位随机抽奖码设计
1. 需求描述
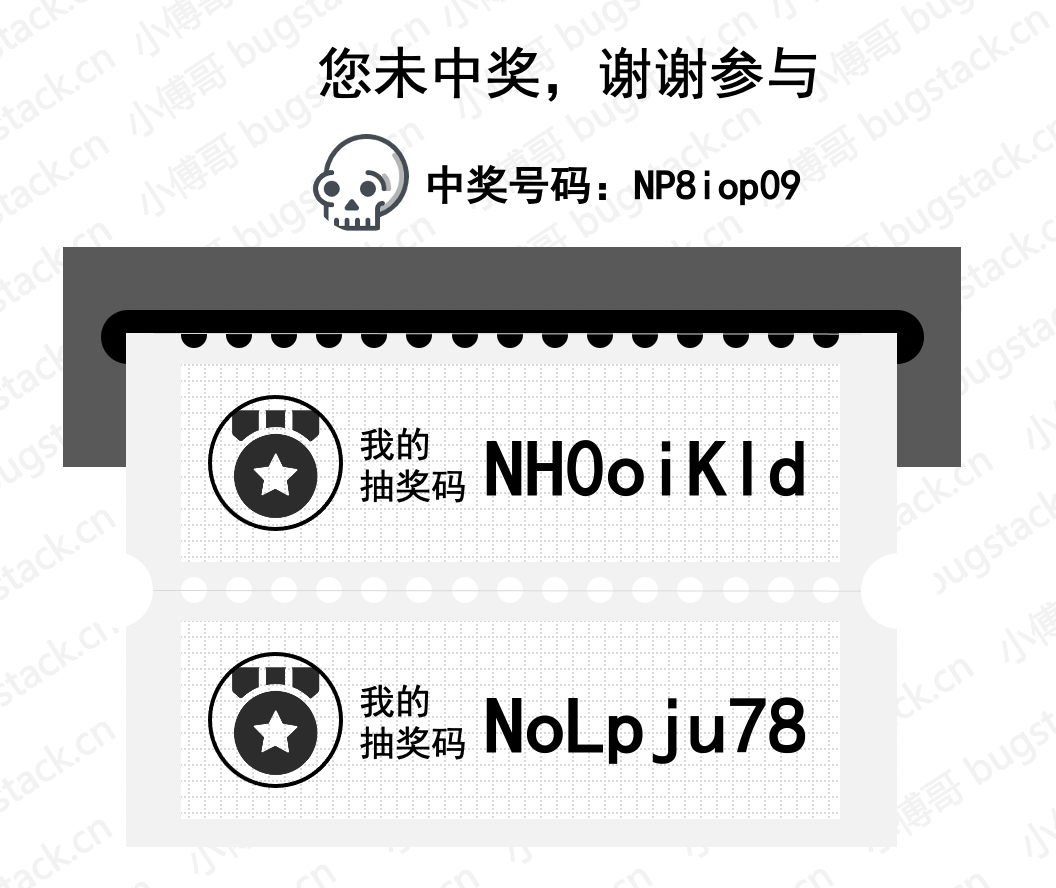
图 15-3 是我们模拟得物APP中关于抽奖码需求的样式图,核心技术点包括:
- 需要一个8位的随机码,全局唯一。
- 每个人可以获得多个这样的随机码,随机码阅读中奖概率越大。
- 随机码我们这里的设计与毒App的展现形式略有不同,组成包括:大写字母、小写字母和数字。
在你没有看实现方案前,你可以先考虑下这样的唯一的随机码该怎样去生成。
2. 实现方案
2.1 基于Redis生成
int codeId = RedisUtil.incr("codeUUID");
String UUID = String.format("%08d", codeId);
System.out.println(UUID);
// 测试结果
00000001
00000002
00000003
- 评分:⭐
- 方案:基于 Redis 的 incr 方法,全局自增从0开始,以上是伪代码。
- 点评:以上方案不可用,除了并不一定能保证全局自增和可靠性外,有一个很大的问题是你的顺序自增,把APP有多少人参加活动的数据暴露了。
2.2 随机数生成
Random random = new Random();
StringBuffer code = new StringBuffer();
for (int i = 0; i < 8; i++) {
int number = random.nextInt(3);
switch (number) {
case 0:
code.append((char) (random.nextInt(26) + 65)); // 65 ~ 90
break;
case 1:
code.append((char) (random.nextInt(26) + 97)); // 97 ~ 122
break;
case 2:
code.append((char) (random.nextInt(9) + 48)); // 48 ~ 97
break;
}
}
System.out.println(code.toString());
// 测试结果
qvY0Fqrk
8uyehK3H
U7z2v4qK
- 评分:⭐⭐
- 方案:基于随机数生成8位随机码,相当于62^8次幂,有将近百万亿的随机数。
- 点评:此方案在很多业务场景中都有使用,但这里的实现还有一个问题,就是随性后的不唯一性,虽然我们知道这么大体量很难出现两个相同的。但如果随着业务运营日积月累的使用,终究会有两个一样的随机数,只要出现就会是客诉。所以还需要保证唯一性,可以在随机数中加入年或者月的标记,按照这个体量落库用防重方式保证唯一。当然你还可以有其他的方式来保证唯一
2.3 基于雪花算法
final static char[] digits = { '0', '1', '3', '2', '4', '7', '6', '5', '8',
'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L',
'9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l',
'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y',
'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y',
'Z', '0', '1', };
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
System.out.println(idWorker.nextId());
long code = idWorker.nextId();
char[] buf = new char[64];
int charPos = 64;
int radix = 1 << 6;
long mask = radix - 1;
do {
buf[--charPos] = digits[(int) (code & mask)];
code >>>= 6;
} while (code != 0);
System.out.println(new String(buf, charPos, (64 - charPos)));
}
// 测试结果
uxdDQOG001
uxd8Uoj001
uxdERuG000
- 评分:⭐⭐⭐
- 方案:基于雪花算法的核心目的是,生成随机串的本身就是唯一值,那么就不需要考虑重复性。只需要将唯一值转换为对应64进制的字符串组合就可以了。
- 点评:这里的思路很好,但有几个问题需要解决。首先是雪花算法的长度是18位,在转换为64位时会会有10位长的随机字符串组合,不满足要求。另外大写字母、小写字母和数字组合是62个,还缺少2个不满足64个,所以需要后面补充两位,但这两位生成的组合数需要废弃。那么,如果按照这个生成随机串且保证唯一的思路,就需要完善雪花算法,降低位数,在满足业务自身的情况下,控制生成长度。
实现方案,终究不会一次就完美,还需要不断的优化完善。除此之外也会有很多其他的思路,例如电商生成订单号的方案也可以考虑设计,另外你以为这就完事了?当你已经工作多年,那么你每一天其实都在解决技术问题也是数学问题,产品的需求也更像是数学作业!加油数学老师!
四、总结
- 好的程序实现离不开数据结构的设计、逻辑算法的完善、设计模式的考量,再配合符合业务发展和程序设计的架构才能搭建出更加合理的程序。
- 在学习的过程中不要刻意去背答案、背套路,那不是理科内容的学习方式。只有你更多的去实践、去验证,让懂了就是真的懂,才更加舒心!
- 本篇又扯到了这,想问一句你是害怕35岁,还是害怕自己能力不及年龄增长?想学就把知识学透,你骗不了面试官,只能骗自己!
五、系列推荐
- 握草,你竟然在代码里下毒!
- 一次代码评审,差点过不了试用期!
- 数据结构,HashCode为什么使用31作为乘数?
- HashMap核心知识,扰动函数、负载因子、扩容链表拆分,深度学习
- HashMap数据插入、查找、删除、遍历,源码分析

(转载本站文章请注明作者和出处 微信公众号:bugstack虫洞栈 | 作者:小傅哥)
Post Directory