# 握草,这些研发事故30%我都干过!
作者:小傅哥
博客:https://bugstack.cn (opens new window)
原文:https://mp.weixin.qq.com/s/9nOkzgbR0Wv6SupMi_2seg (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
# 一、前言
你的代码出过事故吗?
老人言:常在河边走哪有不湿鞋。只要你在做着编程开发的工作就一定会遇到事故,或大或小而已。
当然可能有一部分研发同学,在相对传统的行业或者做着用户体量较小的业务等,很难遇到让人出名的事故,多数都是一些线上的小bug,修复了也就没人问了。
但如果你在较大型的互联网公司,那么你负责的开发的系统功能,可能面对的就是成百万、上千万级别用户体量。哪怕你有一点小bug也会被迅速放大,造成大批量的客诉以及更严重的资金损失风险。就像:
- 拼多多“薅羊毛”事件,朋友圈疯狂转发。
- 淘宝昨现重大线上bug,S1级事故,疑似程序员故意埋雷。
您使用的程序是内测版本,将于当地时间 2020-03-28 到期,到期后将无法使用,请尽快下载最新版本。 - GitHub忘记续订SSL证书导致网站排版混乱,部分网站不能正常打开。
类似这样事故的出现,可能是因为技术流程、方案实现、技术服务以及运营配置等等原因产生的。综合可以概括为以下几点:
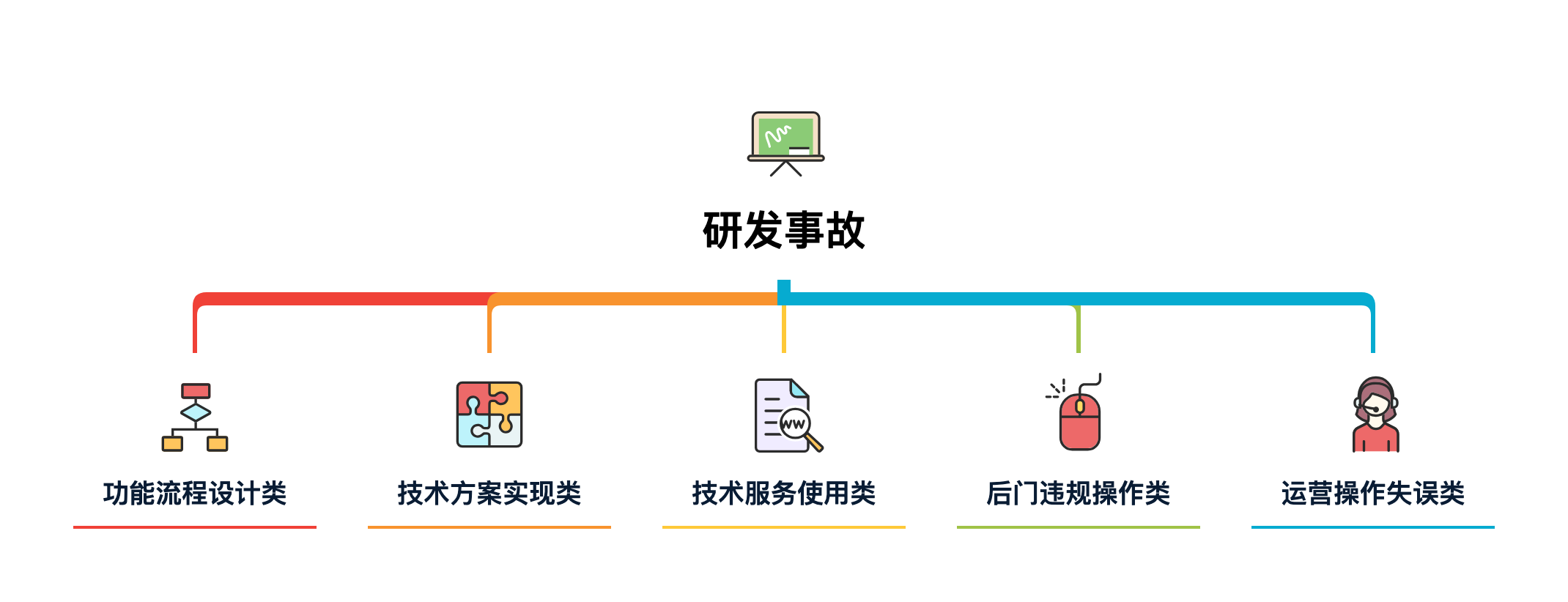
- 功能流程设计类:通常指的是研发在设计产品逻辑功能实现流程中,错误的执行调用关系而造成的风险事故。
- 技术方案实现类:在研发设计好流程后,每一个功能点的实现方案会因人而异,也会由于理解偏差或不足,而导致实现过程中缺少了对代码在运行过程中健壮性的评估。
- 技术服务使用类:这一类说的是在研发使用数据库服务、缓存服务、大数据服务、配置中心服务以及发布上线服务等时,对各项服务的配置以及使用上缺少一定的了解,而造成的事故。
- 后门违规操作类:这一类因公司对研发规范的执行强度不同,而是否会有此类风险。例如:有些研发同学会开发一些后门程序,比如可以在某个ERP页面执行数据库语句,临时修改数据。这样造成的风险,通常为后门违规操作,会有开除风险。
- 运营操作失误类:在研发以为还有一部分公司内的伙伴会使用研发同学开发的运营系统,配置活动、变更用户、执行流程等操作,但一般情况下这类系统缺少一定的强规则验证,导致运营小白在操作过程中造成风险,从而引发事故。一般线上配置出错误卷,或者推错短信给用户等等,都是这样发生的。
可以说,大多数比较蠢的事故主要是个人责任心问题。但那些有技术含量的事故,犯一次还是挺值得的。虽然公司很讨厌你造成事故,因为会给公司带来损失嘛!但这样具有具有技术含量的事故,却对你个人成长非常好的案例。不过禁酒虽好,可不能贪杯!
接下来,小傅哥就带着你领略下各类事故的风采,看看在什么场景、遇到什么问题、怎么解决的以及能学到什么!
# 二、研发事故
# 1. 功能流程设计类
- 事故级别:P1
- 事故判责:相应的研发、测试总结复盘,罚款50元给参加的会议的伙伴买棒棒糖以示警告。
- 事故名称:抽奖积分支付流程不合理
- 事故现象:用户积分多支付,造成批量客诉,当天紧急排查修复,并给用户补充积分。
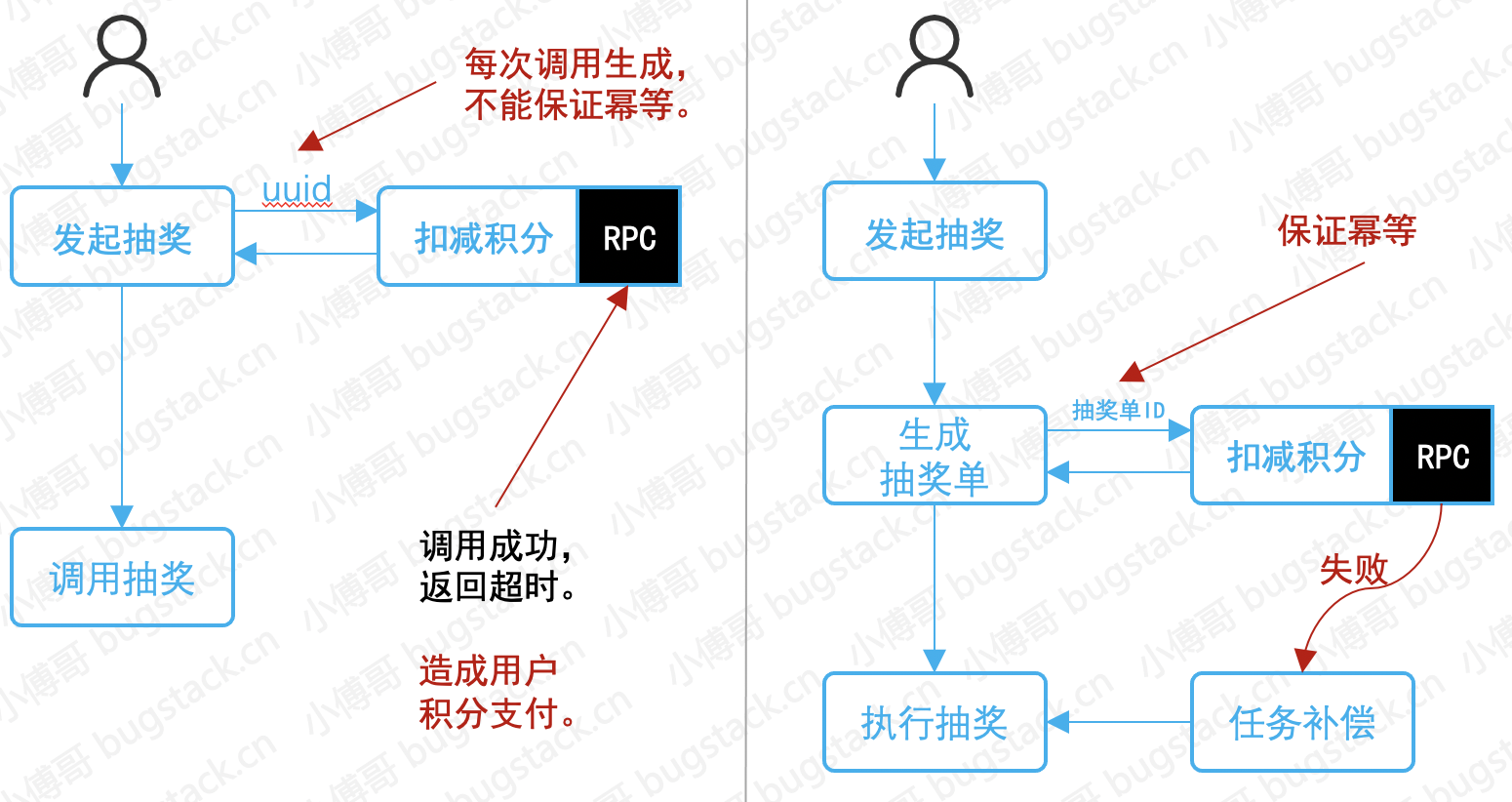
- 事故描述:这个产品功能的背景可能很大一部分研发都参与开发过,简单说就是满足用户使用积分抽奖的一个需求。上图左侧就是研发最开始设计的流程,通过RPC接口扣减用户积分,扣减成功后进行抽奖。但由于当天RPC服务不稳定,造成RPC实际调用成功,但返回超时失败。而调用RPC接口的uuid是每次自动生成的,不具备调用幂等性。所以造成了用户积分多支付现象。
- 事故处理:事故后修改抽奖流程,先生成待抽奖的抽奖单,由抽奖单ID调用RPC接口,保证接口幂等性。在RPC接口失败时由定时任务补偿的方式执行抽奖。流程整改后发现,补偿任务每周发生1~3次,那么也就是证明了RPC接口确实有可用率问题,同时也说明很久之前就有流程问题,但由于用户客诉较少,所以没有反馈。
- 学习总结: 调用的接口、发送的MQ,并不一定会每次都成功。那么一定要做好幂等性以及失败后的补偿,来把整个技术实现流程做的更加完善。就像小傅哥说的,擦屁屁的纸80%的面积其实都是保护手的!
网友事故分享:
| 事故名称 | 事故描述 | 事故结果 |
|---|---|---|
| 业务流程搞错+代码频繁开辟线程池 | 业务流程搞错导致的问题就是改动特别大,有点类似重构代码了哎西,导致服务宕机很久,客户疯狂反馈 | 疯狂加班改业务,加了不知道多少个晚上,由于是菜狗子,写的代码太垃圾了,被大佬给疯狂叼 |
| 线上修改用户收货地址失败(同事需要的问题,也可以借鉴下^v^) | 场景:客服反应用户需要把收货地址从河北省改为浙江省(因为疫情),公司要求修改线上数据需要提交工单,因此l到审核平台提交申请等一系列流程。 问题:工单显示修改结果成功,但是数据没有改过来,多为同事一起查看sql发现sql编写没有问题。 解决过程:检查sql是否正确,平台是否修改成功,又检查了数据是否正确,还检查了修改时间是没有问题的。 | 首先,忽略了一个问题,这个订单数据是淘宝下单同步到我们订单这边的,数据修改的后,淘宝又同步也数据过来,把修改正确的数据又改为了河北的地址。然后就怀疑sql审核平台问题。到这里故事已经讲完了。结论:想告诉大家要相信代码,多检查不确定的情况,不要钻到死胡同,老是怀疑审核平台问题,多检查自身问题。 |
| 业务相关事故 | 刚加入一个新的团队,没有深入了解别人的代码就进行复用,没有理解业务的场景就限制条件,类似的情况很多,只能说,再简单的代码都要保持敬畏,因为你不知道哪里会出问题 | 用户投诉、领导批评 |
# 2. 技术方案实现类
- 事故级别:P0
- 事故判责:营销活动推广用户较多,影响范围较大,研发整改代码并做复盘。
- 事故名称:秒杀方案独占竞态实现问题
- 事故现象:用户看到可以购买,但只要一点下单就
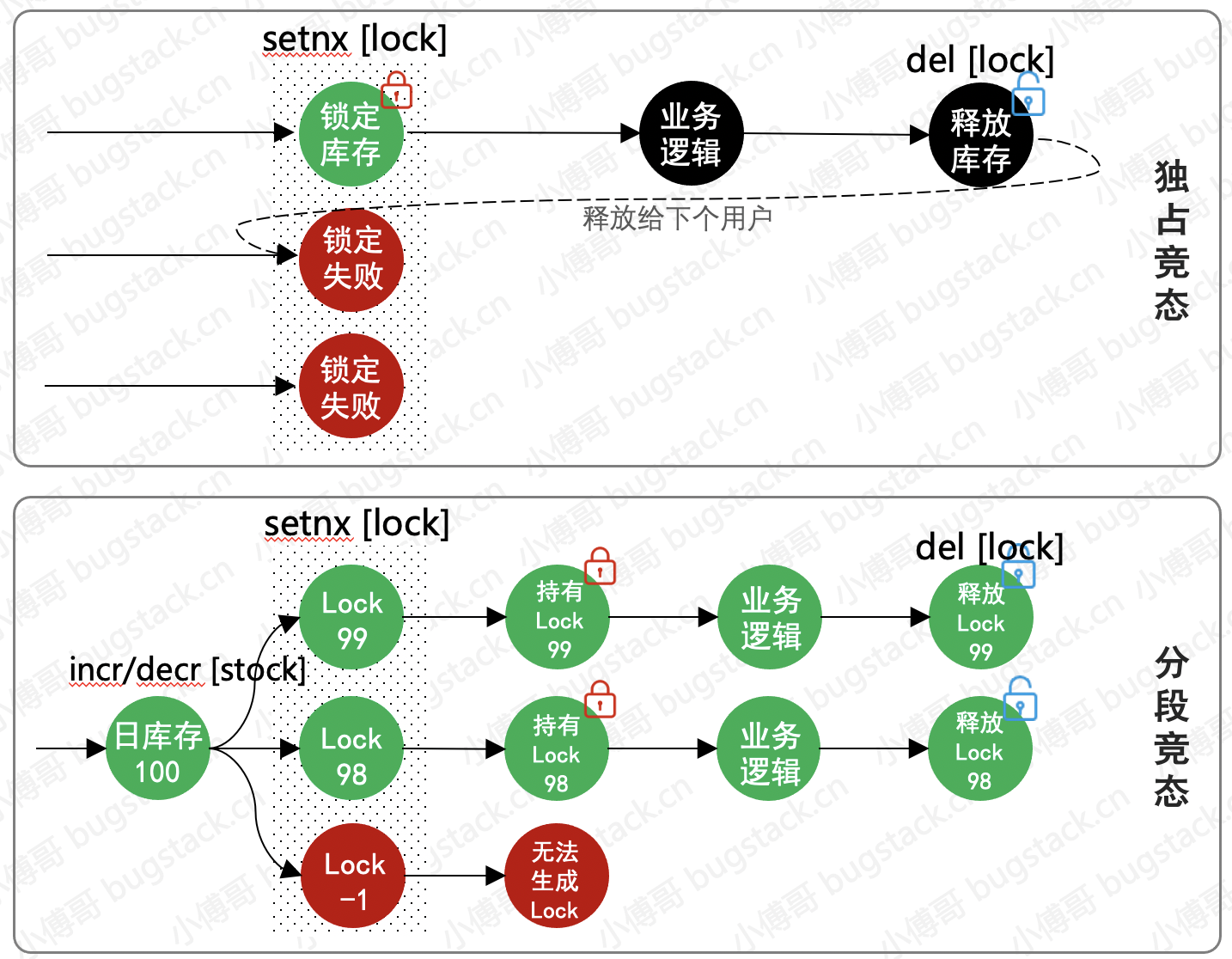
活动太火爆,换个小手试试。造成了大量客诉,紧急下线活动排查。 - 事故描述:这个一个商品活动秒杀的实现方案,最开始的设计是基于一个活动号ID进行锁定,秒杀时锁定这个ID,用户购买完后就进行释放。但在大量用户抢购时,出现了秒杀分布式锁后的业务逻辑处理中发生异常,释放锁失败。导致所有的用户都不能再拿到锁,也就造成了有商品但不能下单的问题。
- 事故处理:优化独占竞态为分段静态,将活动ID+库存编号作为动态锁标识。当前秒杀的用户如果发生锁失败那么后面的用户可以继续秒杀不受影响。而失败的锁会有worker进行补偿恢复,那么最终会避免超卖以及不能售卖。
- 学习总结: 核心的技术实现需要经过大量的数据验证以及压测,否则各个场景下很难评估是否会有风险。当然这也不是唯一的实现方案,可以根据不同的场景有不同的实现处理。
网友事故分享:
| 事故名称 | 事故描述 | 事故结果 |
|---|---|---|
| gc疯狂回收 | 最近调整了自己业余项目,跑一段时间就内存狂涨,还不能主动诱发 | dump内存中 |
| 重复扣入账 | 并发数过多,数据库连接满,等待超时,session断开。事务未提交,捞出继续干 | 500块,深入并发编程,目前并发模型在我心中,欢迎battle |
| 数据覆盖 | 循环更新数据时,开启事务,持续时间过长,然后覆盖掉了用户在持续事务中提交的数据 | 没影响,就是多加了几天班 |
| 数据穿透 | 第三分使用脚本海里请求并发造成数据穿透 | 削峰天谷, 使用队列处理请求 |
| 这序列号咋重复了?? | 序列号应具有全局的唯一,一条数据代表一条收入,序列号生成规则+代码bug导致序列号重复,影响了几万单收入核对 | 一级事故,回溯+通报 |
| 业务流程数据覆盖 | 启流程是一个公共类,各种交易都在这个里面做,公共类一开始没有经过设计,有一个方法返回了这个模板类型字段,同时这个方法又是一个检验类,当时加了一个检验返回成错误码了,导致所有的交易都启不了流程。 | 挨批长记性。。。 |
| simpledateformat的线程不安全导致多线程定时任务解析日期出错 | 某定时任务运行时,需要做一些日期解析动作,就用了一个公共变量simpledateformat,来格式化,结果任务经常间歇性报错,几天报一次或者一两周报一次,没啥规律。看异常信息才发现解析日期的字符串很奇怪,经常出现很多奇奇怪怪的数字。 | 定时任务报错,不过还好,定时任务只是为了做缓存而已,不涉及到数据库的更新,仅仅是查询而已。 |
| 前端解析主键异常 | 由于Long类型最大19位而JavaScript最大接收数字为16位,固存在精度丢失问题 | 统一处理将id转字符串再返回前端 |
| list遍历删除 | 遍历删除清空list数组,为了节省计数器那小小一点内存,日了 | 报错被叼了呗,为啥不用计数器?不香吗? |
| 商品超卖 | 售卖一个兄弟部门的电子券商品,同步库存的代码有问题,导致了超卖 对客户造成了损失 | 罚款1000元 |
# 3. 技术服务使用类
- 事故级别:P2
- 事故判责:网友说被叼了一会,问题不大!
- 事故名称:扩容时忽略了连接池梳理,导致连接池被打满
- 事故现象:线上突然收到报警短信,打开电脑一看,简单的查询接口超时到3分钟才返回。
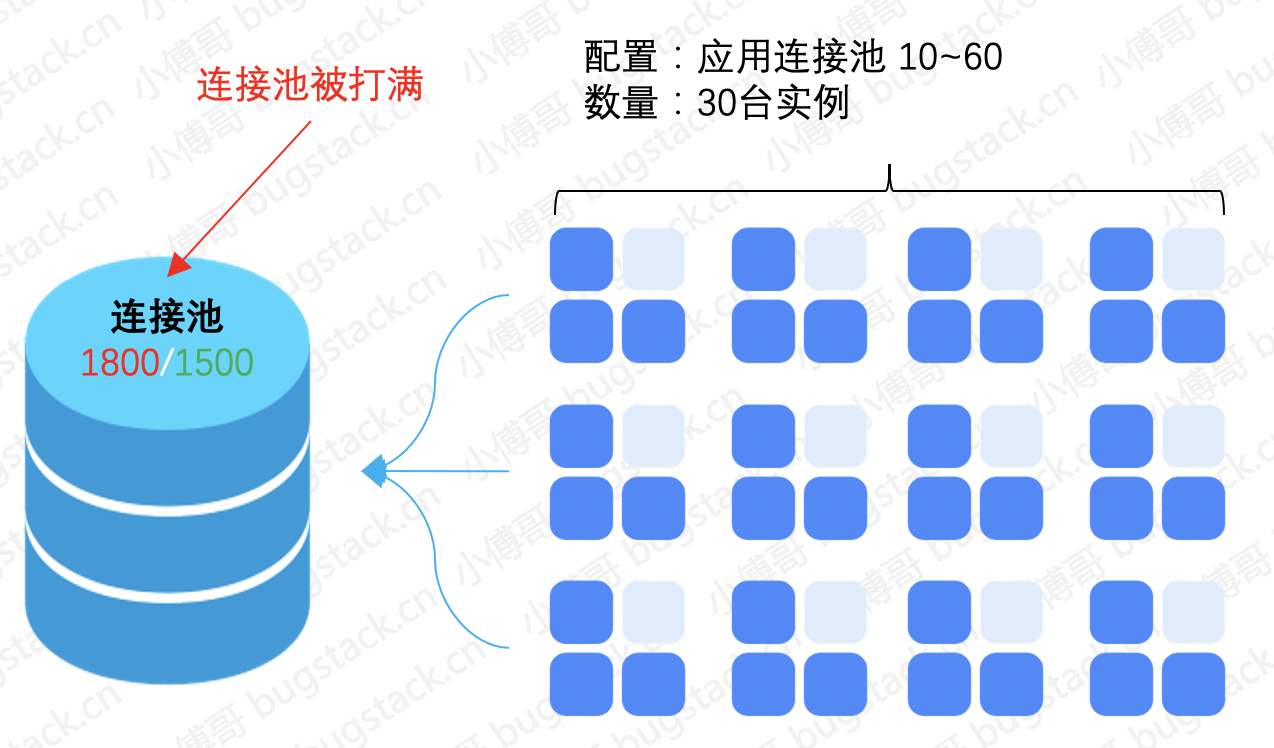
- 事故描述:幸好监控报警加的全,及时收到了报警短信,联系DBA检查发现连接池被打满了。为了快速解决线上报警,优先临时扩容了连接池以及把服务重启。观察后连接池打满消失了。
- 事故处理:检查应用数据库连接池配置,以及额外不经常上线的服务一并排查。经查询发现所有的应用加起来连接池的最高配置超过数据库分配的连接池数量。尤其是定时任务较长时间扫库处理,是直接导致连接池打满的重要原因。
- 学习总结: 研发不仅是代码开发搬砖人员,还要了解熟悉与之配套的服务。合理的使用、全面的考量才能避免一些看似不应该出现的事故问题。
网友事故分享:
| 事故名称 | 事故描述 | 事故结果 |
|---|---|---|
| 使用fastjson | 全身上下都是高危漏洞,一年不停升级版本打补丁 | 珍惜生命,远离fastjson |
| 微信名存储bug | 微信名的emj头等存入mysql编码是utf8的库报错 | 被怼了!改成utf8mb4编码 |
| 磁盘不足 | 数据库集群磁盘空间不足,提前两周提交扩容申请,甲方运维没提交上去,最后某台机器空间不足,导致整个集群彻底不能工作,体验一把某国产号称可以方便横向扩容的某idb的优越性 | 罚款,责任归系统建设方 |
# 4. 后门违规操作类
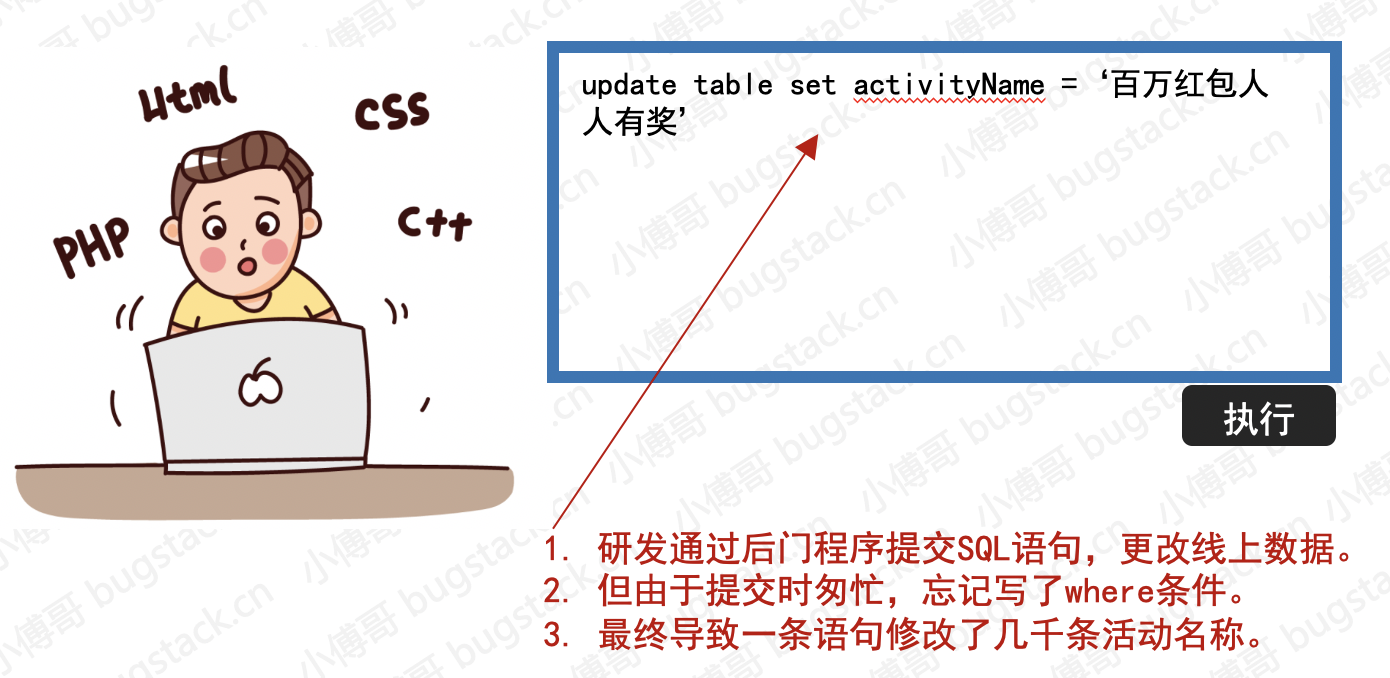
- 事故级别:P0
- 事故判责:网友反馈,私自开发后门,执行sql错误,影响较大。开除!
- 事故名称:通过后门程序修改线上数据
- 事故现象:这次修改影响范围比想象的要小,只有部分数据因为缓存失效了,才读取数据库的活动信息。所有有少部分客诉说活动与名称不符合。
- 事故描述:研发人员应运营要求修改线上配置错误的活动名称,但任何邮件记录以及负责人审批。所以只是研发私自通过后门程序提交sql语句修改,但忘记写where条件,造成几千条活动名称被同时修改。
- 事故处理:事后联系DBA紧急通过binlog日志进行数据修复。
- 学习总结: 研发人员应避免操作线上数据,尤其是变更数据类。也不要开发各类改数据、上线、传配置文件等后门。而应该严格遵守研发流程,紧急事情需要请求批准处理。
网友事故分享:
| 事故名称 | 事故描述 | 事故结果 |
|---|---|---|
| 删除整个项目目录文件 | 测试区,测试删除文件时目录写错,导致整个weblogic子项目目录被删 | 请项目中负责集成部署的公司帮忙重新部署,测试区瘫痪了两天 |
| 误更新生产订单数据3万多条 | 下班前,未带核心过滤条件,导致误更新3万多条订单数据,偷偷利用binlog恢复了,耗时3个小时 | 完美恢复数据 |
| 线上库整库误删除 | 应业务方要求要在线上环境创建线上联调库,使用了导出数据库DDL语句后,直接执行,导致执行了exists drop语句,删除了线上库所有数据,数据量大表均在千万级,APP、网站全线瘫痪。 | 使用前一天的备份副本数据恢复,下载binlog日志按操作避开事发时间点分割后编译,导入数据,然后再修复事故之后的数据,共计耗时48小时。 |
# 5. 运营操作失误类

- 事故级别:P2
- 事故判责:网友说,金额太大没发出去!被喷了一会!
- 事故名称:运营把券配置成红包
- 事故现象:线上用户客诉,看到几百亿大的红包,领不到!
- 事故描述:运营人员配置优惠券,但是类型选成了红包,导致页面展示出超大额的红包金额待领取,都超出屏幕长度了!
- 事故处理:紧急下线活动,重新配置上线。同时产品设计需求,由研发人员实现对于此类配置提供明确、醒目的配置和完整的审核流程。如果配置红包、优惠券,会有校验此券的是否存在以及红包最大金额限制。
- 学习总结: 看上去是运营配置错误,但从某个角度看其实也可以说是研发在做功能实现时,太过于单一完成产品功能,而没有加深考虑以及产品的易用性。有时候多问一句就少一个风险!
网友事故分享:
| 事故名称 | 事故描述 | 事故结果 |
|---|---|---|
| 业务漏洞 | 业务乱配优惠券,可以叠加,超级优惠,然后被薅羊毛 | 部门帮着查羊毛记录,处理订单,挽回损失。然后对外发公告宣称是被部门的风控系统误杀的。 |
| 贷款费率 | 运营配置T+1日结算贷款费率错误,导致用户贷款金额发生错误。 | 上线新费率替换旧费率,已经产生的费率错误联系贷款用户修复。 |
| 多活动互斥 | 三个部门的都做活动,但最后导致重复发奖。一个用户邀请别人奖励,变成了三份奖励。 | 产品提供渠道和互斥功能,让运营自己选择是否可以并行发放奖励。 |
# 三、总结
- 讲道理,开发没事故,不是没用户体量,就是没用户规模。否则只要是人就一定会出现事故,要不是小bug被你销声匿迹隐藏了,或者是大事故被喷了或者送飞机了。
- 而尽可能减少事故的方式是需要尽可能按照一定的研发流程来实现功能逻辑。就像:
设计评审,把控的是实现流程、代码评审,把控的是实现方案,在配合上完善的监控和报警。只有这样才能更少的减少不必要的事故。 - 关于研发在职场中的事故本文就讲到这了,感谢粉丝分享出自己的遇到的事故,让大家可以互相学习,减少离职扣工资的风险。😄多关注小傅哥,一个写有价值原创好文章的男人!
京ICP备19031103号 | 
京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.