# 面试官:“程序内存溢出,你怎么找出大对虾(像)”? —— arthas 使用教程
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
大家好,我是技术UP主小傅哥。
👬🏻 兄弟,你被看过手相不,你被号过脉相没。一个没与你生活过就知道你的过去和现在,一个不了解你的日常就知道你是否怀孕是男是女。而你自己亲手开发的Java代码,上线后报错都不知道怎么发生的!!!咋办?

那有什么手段给 Java 代码号脉吗?🤔
还真有这么一个工具,也是大多数老司机程序员👨🏻💻非常喜欢用的一款组件,很多时候不好排查的 Bug 都用这个工具进行分析。它可以知道哪个对象创建的过多、方法的出入参、系统运行时候JVM的参数等等,让你随时可以知道系统运行的细节状态。
它就是 Arthas,但很多伙伴还没有使用过,这篇文章为大家分享下,如何使用这样一款组件。以及怎么使用这个组件监控部署到 Docker 中的 Java 应用。
# 一、组件介绍
官网:https://arthas.aliyun.com/doc/ (opens new window)
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到 JVM 的实时运行状态?
- 怎么快速定位应用的热点,生成火焰图?
- 怎样直接从 JVM 内查找某个类的实例?
# 二、快速入门
在 Arthas 官网有一个简单🔜快速入门的案例,它提供了2个程序,一个是 Java 的随机数分解的程序代码,另外一个是 arthas-boot.jar 监控组件。这个套代码可以在任何安装了 Java 环境的服务器上使用,包括你本地、云服务器都可以运行。
# 1. 步骤1,案例程序
curl -O https://arthas.aliyun.com/math-game.jar
java -jar math-game.jar
2
# 2. 步骤2,监控程序
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
2
- 启动后会出来一个 math-game.jar 之后再敲下回车,就进入了 Arthas 的监控程序了。之后你可以使用监控程序提供的各种命令进行使用。
- 命令列表:https://arthas.aliyun.com/doc/commands.html (opens new window)
# 三、应用使用
# 1. 环境准备
为了方便大家进行学习验证,小傅哥这里准备好了一个测试工程和相关的环境安装。你可以如下文的说明进行使用和验证。
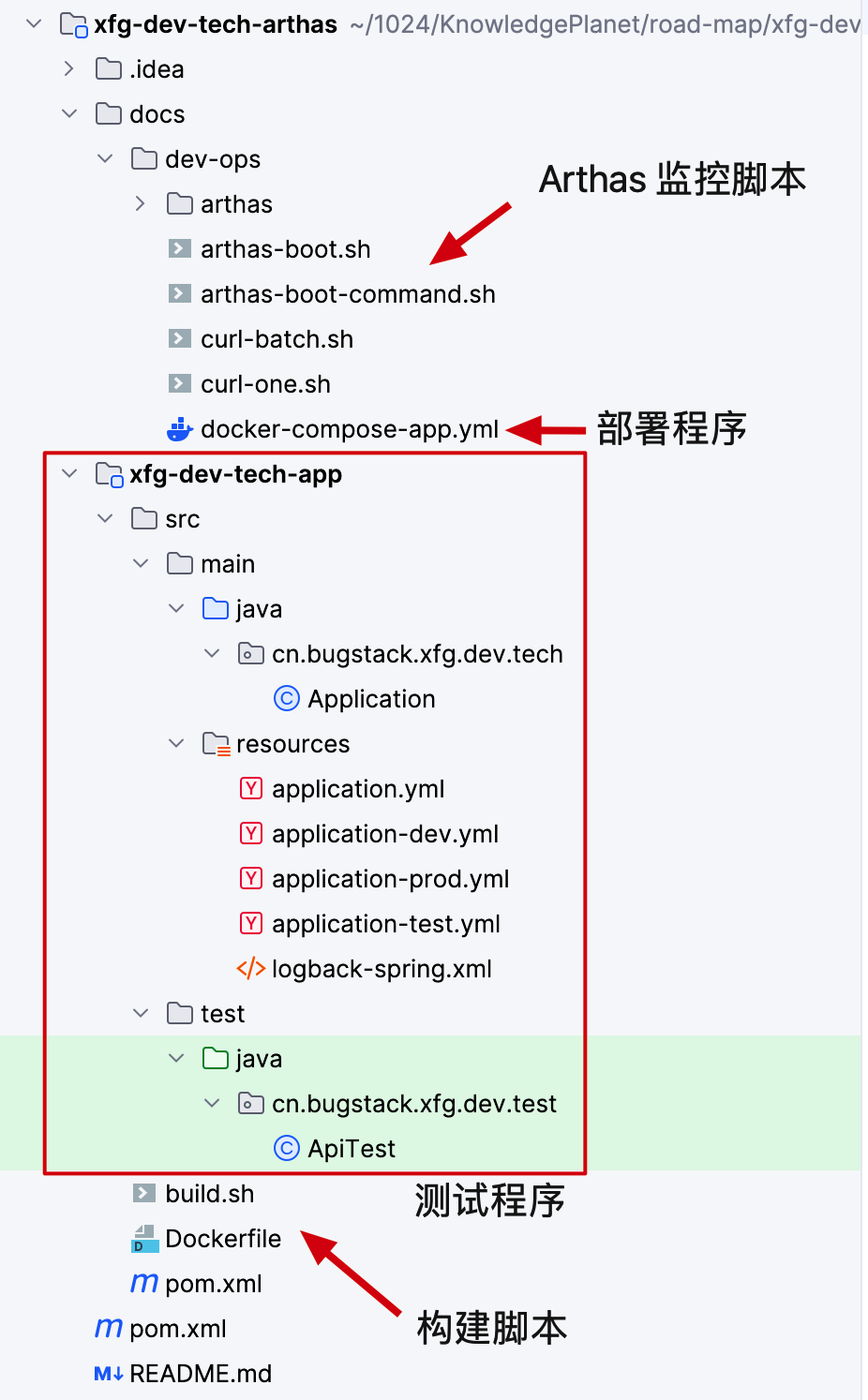
- 工程:https://github.com/fuzhengwei/xfg-dev-tech-arthas (opens new window)
- 说明:
dev-ops下提供了部署测试工程的 docker compose 脚本,以及 arthas-boot 启动程序的脚本。另外工程提供了一个接口,每次访问都会创建对象。接口在 Application 中,简单实现。地址:http://localhost:8091/api/exec (opens new window) - 接口内容可详见代码。 - 前置:如果你需要云服务器部署操作,可以在 bugstack.cn (opens new window) <路书> 中有云服务器操作,可以学习使用。
# 2. 应用安装
操作过程预览
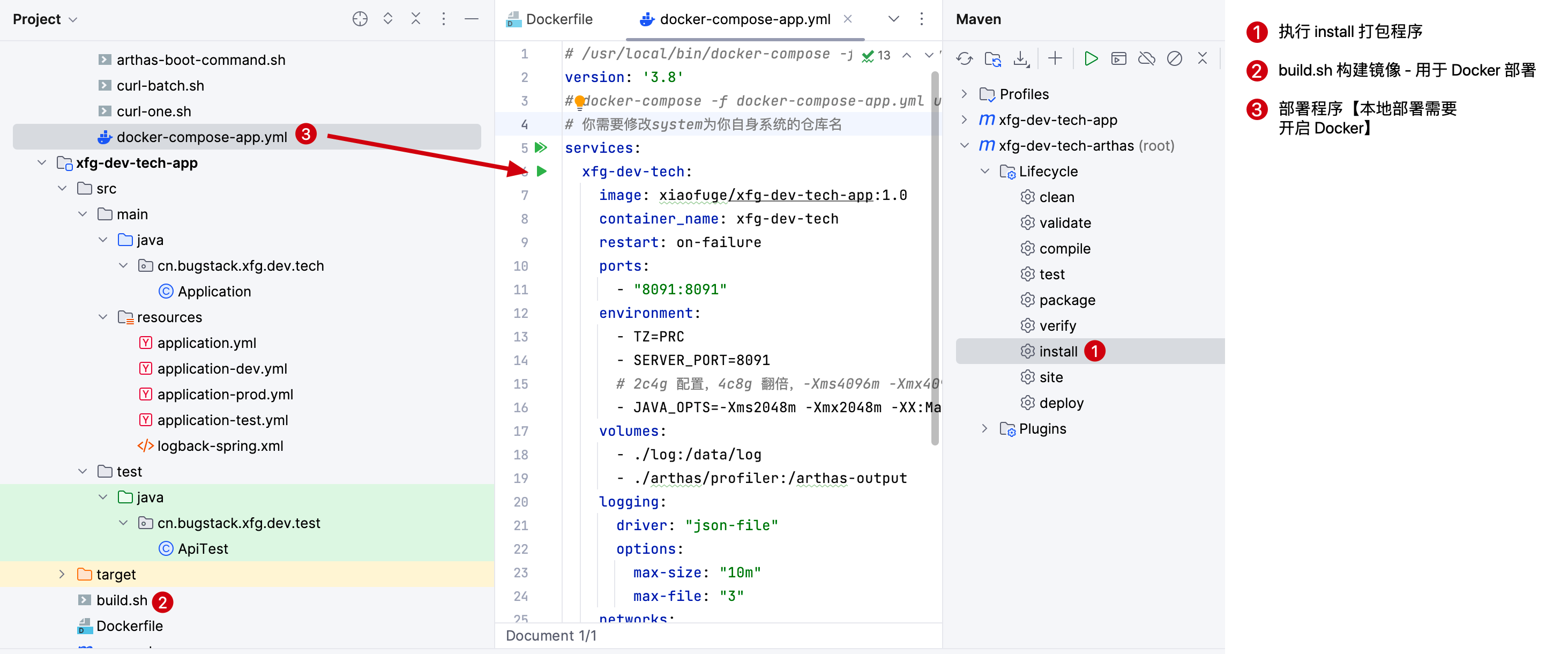
如图所示,接下来我们会进行部署操作。
# 2.1 构建脚本
# 基础镜像 openjdk:8-jre-slim openjdk:8-jdk-alpine 8-jdk-alpine
FROM openjdk:8-jdk
# 作者
MAINTAINER xiaofuge
# 配置
ENV PARAMS=""
# 时区
ENV TZ=PRC
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 添加应用
ADD target/xfg-dev-tech-app.jar /xfg-dev-tech-app.jar
# arthas https://hub.docker.com/r/hengyunabc/arthas
COPY --from=hengyunabc/arthas:latest /opt/arthas /opt/arthas
## 在镜像运行为容器后执行的命令
ENTRYPOINT ["sh","-c","java -Djava.security.egd=file:/dev/./urandom -jar $JAVA_OPTS /xfg-dev-tech-app.jar $PARAMS"]
# 暴露容器的端口
EXPOSE 8989
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
FROM openjdk:8-jdk:因为 arthas 需要 jps 的相关命令,所以需要指定安装 jdk 版本。openjdk:8-jre-slim是没有这些脚本的。hengyunabc/arthas:latest:把 arthas 的镜像打包到程序中,这样我们可以直接在程序中使用 arthas 组件。- 构建过程:无论是本地还是云服务器 Docker 启动后,先执行
maven install程序、后执行build.sh构建应用镜像。云服务器操作视频 (opens new window)
# 2.2 部署项目
version: '3.8'
# docker-compose -f docker-compose-app.yml up -d
# 你需要修改system为你自身系统的仓库名
services:
xfg-dev-tech:
image: xiaofuge/xfg-dev-tech-app:1.0
container_name: xfg-dev-tech
restart: on-failure
ports:
- "8091:8091"
environment:
- TZ=PRC
- SERVER_PORT=8091
# 2c4g 配置,4c8g 翻倍,-Xms4096m -Xmx4096m | -Xmx –Xms:指定java堆最大值(默认值是物理内存的1/4(<1GB))和初始java堆最小值(默认值是物理内存的1/64(<1GB))
- JAVA_OPTS=-Xms2048m -Xmx2048m -XX:MaxMetaspaceSize=128m -XX:MetaspaceSize=128m -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDateStamps
volumes:
- ./log:/data/log
- ./arthas/profiler:/arthas-output
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
networks:
- my-network
networks:
my-network:
driver: bridge
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
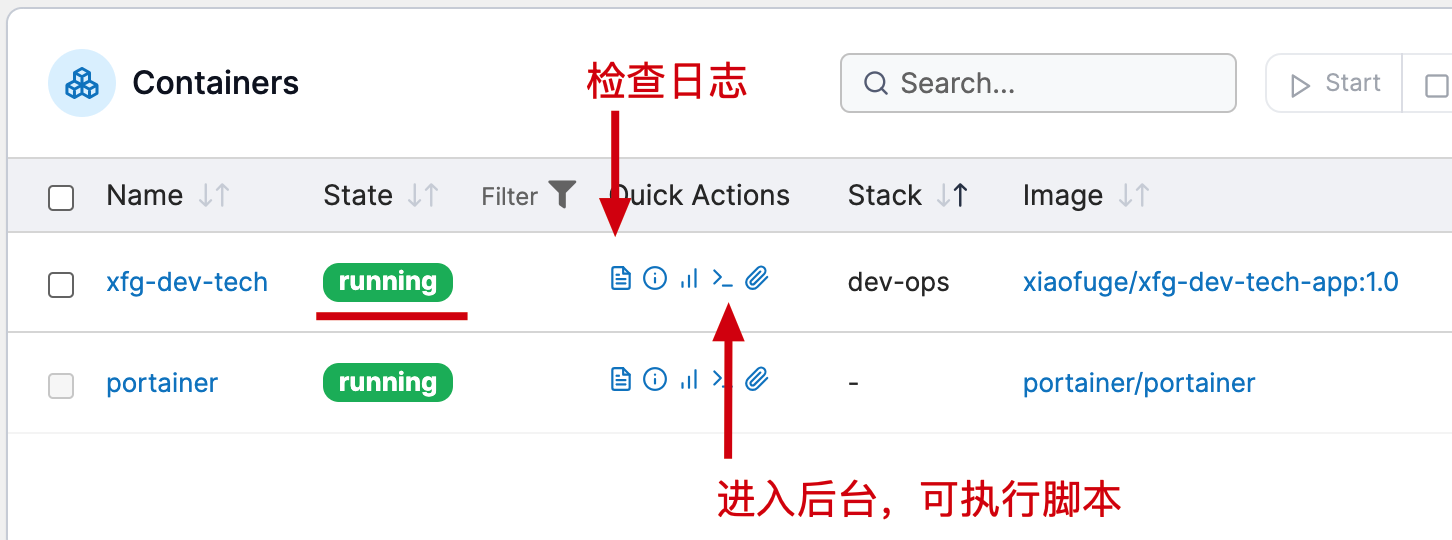
- 脚本说明;脚本提供了 docker compose 安装的配置参数,包括端口、jvm、日志和arthas的映射路径等。
- 执行脚本;
docker-compose -f docker-compose-app.yml up -d这样会帮助你启动项目。 - Mac 电脑 + Docker 可以直接在 IntelliJ IDEA 中点击启动。
# 3. 监控部署
docker exec -it xfg-dev-tech /bin/sh -c "java -jar /opt/arthas/arthas-boot.jar"
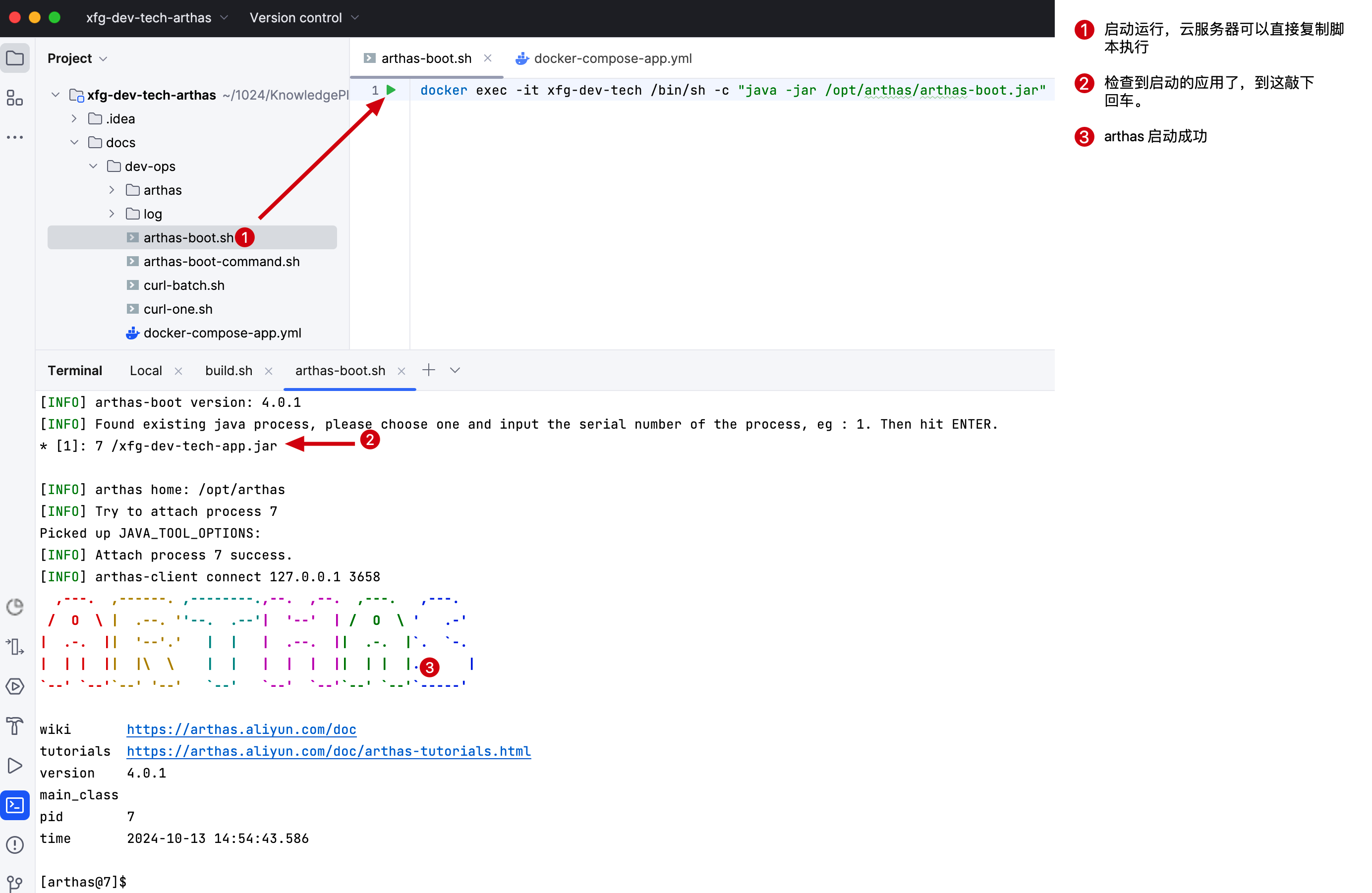
- 在案例工程下有一个 dev-ops/arthas-boot.sh 你可以执行启动 arthas
- 启动后有一个 arthas 的控制台,这个控制台可以输入各种 arthas 提供的命令来监控程序。非常强大
# 4. 访问接口
在案例工程中提供了一个用于创建对象的程序,方便进行测试。
@Slf4j
@SpringBootApplication
@RestController()
@RequestMapping("/api/")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
// 创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
// 用于存储内存占用对象的列表
private static final List<Object> memoryHolder = new ArrayList<>();
/**
* http://localhost:8091/api/exec
*/
@RequestMapping(value = "/exec", method = RequestMethod.GET)
public String exec() {
executorService.submit(() -> {
try {
// 创建一个大对象
// byte[] largeObject = new byte[10 * 1024 * 1024]; // 10MB
byte[] largeObject = new byte[10 * 1024]; // 10MB
// 将其加入内存占用列表中,防止被gc
synchronized (memoryHolder) {
memoryHolder.add(largeObject);
}
log.info("模拟填充大对象");
// 模拟一些工作
Thread.sleep(1000);
} catch (OutOfMemoryError e) {
System.err.println("Out of memory! Halting further allocation.");
// 如果出现OOM,暂停分配以防止程序崩溃
executorService.shutdown();
} catch (InterruptedException e) {
// 捕获并处理睡眠中断
Thread.currentThread().interrupt();
System.err.println("Task interrupted");
}
});
return "ok";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
- 请求地址:http://localhost:8091/api/exec (opens new window)
- 请求脚本:提供了请求1次和循环多次的脚本,方便测试。
# 四、命令使用
使用监控命令前,可以先执行上图中的 curl-one.sh 调用程序接口。你还可以在使用命令的过程中调用测试。
命令:https://arthas.aliyun.com/doc/commands.html (opens new window)
# 4.1 dashboard - 当前系统的实时数据面板
[arthas@7]$ dashboard
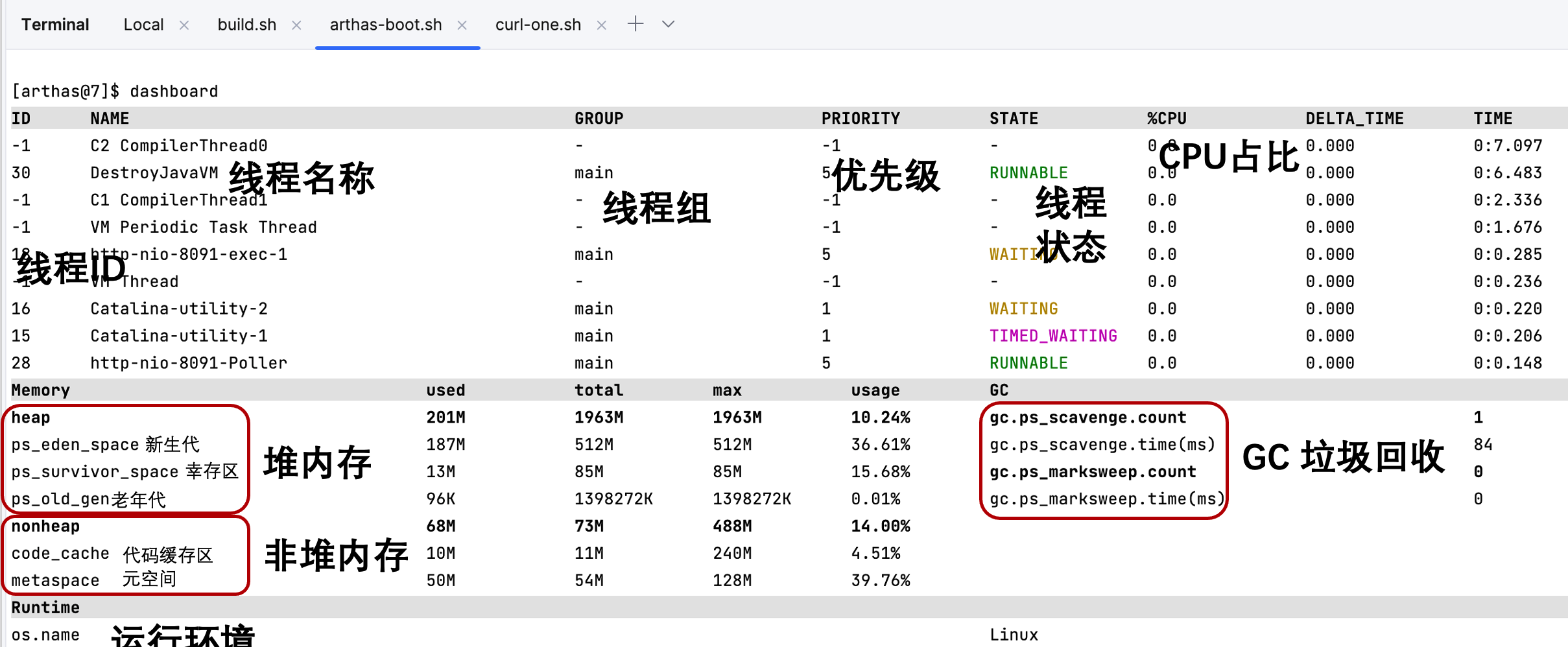
- 运行脚本后,可以查看到当前服务的运行数据信息。另外这里还有一些 JVM 基础知识,补充给大家。
# 4.1.1 jvm 内存空间都有啥
在 Java 运行环境中,JVM(Java Virtual Machine, Java 虚拟机)是执行 Java 程序的引擎,而内存管理是 JVM 非常重要的一部分。JDK 1.8 中的 JVM 内存空间主要分为以下几个区域,每个区域都有其特定的用途:
堆(Heap):
- 用途:堆是 JVM 中内存最大的一块,用于存储所有的对象实例和数组。几乎所有对象都在此分配内存,垃圾收集器也在这里执行。
- 分代垃圾收集机制:堆内存被进一步划分为新生代和老年代。
- 新生代(Young Generation):用于存放新创建的对象。其中又分为伊甸园区(Eden Space)和两个幸存者区(Survivor Spaces,通常称为 S0 和 S1)。
- 老年代(Old Generation):用于存放生命周期较长的对象。
方法区(Method Area)(在 JDK 1.8 中已被细化为元空间 Metaspace):
- 用途:存储已被加载的类元数据、常量、静态变量等。在 JDK 1.8 中,用于取代永久代(PermGen)。
- 元空间(Metaspace):与永久代不同,元空间用的是本地内存而不是堆内存,这避免了 Java 中永久代容量不足导致的内存问题。
栈(Stack):
- 用途:每个线程创建时会分配一个栈,它用来存储局部变量表、操作数栈、动态链接、方法出口等。栈内存会自动随着方法的进出而分配和释放。
- 特性:栈是线程私有的,每个线程都有自己的栈。
程序计数器(Program Counter Register):
- 用途:是一个较小的内存空间,用于指示当前线程所执行的字节码的行号。
- 特性:它是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区。
本地方法栈(Native Method Stack):
- 用途:与 Java 栈类似,但它主要用于处理本地方法(Native Method)的执行。
- 特性:也是线程私有的,负责本地方法的调度和执行。
这些内存区的设计是为了支持 Java 的垃圾收集机制和多线程并发运行,确保 Java 应用程序能够高效和稳定地执行。了解这些内存区的功能和作用,可以帮助开发者优化 Java 应用的性能,并有效管理内存使用。
# 4.1.2 垃圾回收算法
GC 核心在于通过不同的算法来高效管理内存资源。常用的 GC 算法包括:
标记-清除算法(Mark and Sweep):
- 标记阶段:遍历所有的对象引用,标记活动的对象。
- 清除阶段:清理掉未被标记的对象。
- 缺点:容易造成内存碎片,因为清除后内存是不连续的。
复制算法(Copying):
- 将活动的对象从一块内存(From space)复制到另一块(To space),然后清理整块 From space。
- 优点:内存分配简单,不会产生碎片。
- 缺点:需要预留多余的内存空间实行复制。
标记-整理算法(Mark-Compact):
- 标记阶段:和标记-清除相似。
- 整理阶段:将所有活动对象移到一端,处理剩余的空间为可用。
- 减少了碎片化问题,但相比复制算法更复杂。
分代收集算法:
- 根据对象的生命周期不同,将堆分为新生代和老年代。
- 新生代使用复制算法,老年代使用标记-清除 或 标记-整理。
- 优点:优化了大多数对象短命这一特性带来的效率。垃圾回收算法。
# 4.1.3 垃圾收集器
Java 提供了多种垃圾收集器,适用于不同应用场景:
Serial GC:
- 单线程收集器,非常适合单线程环境和小型应用。
- 效率高但可能造成长时间的停顿。
Parallel GC (Throughput Collector):
- 多线程收集器,用于最大化 CPU 吞吐量。
- 适合后台处理任务和高效利用系统资源的场景。
CMS GC (Concurrent Mark-Sweep Collector):
- 重点在于缩短停顿时间,适合响应时间敏感的应用。
- 较轻量级的 GC,但处理老年代垃圾时效率不如 Parallel。
G1 GC (Garbage-First Collector):
- 设计用于大堆,提供可预测的停顿时间。
- 将堆划分为不同的区域(Region),针对不同老化级别进行回收。
ZGC / Shenandoah GC:
- 尝试实现低延迟垃圾回收,几乎不会造成任何长时间的停顿。
# 4.1.4 code_cache (代码缓存区)、compressed_class_space (压缩类空间)、metaspace (元空间),他们的用途是什么,有什么要注意的。
在 Java 虚拟机(JVM)中,非堆内存部分包括多个区域,每个区域负责存储不同种类的数据,这里重点介绍 Code Cache(代码缓存区)、Compressed Class Space(压缩类空间)和 Metaspace(元空间)的用途及注意事项。
# 1. Code Cache(代码缓存区)
用途:
- JIT 编译代码:Java 虚拟机的即时编译器(Just-In-Time Compiler,JIT)会将频繁使用的字节码编译成本地机器码,以提高运行性能。编译后的本地代码存储在代码缓存区中。
- 性能提升:通过存储这些编译后的代码,JVM 可以避免对同一代码片段重复进行解释,从而提升执行速度。
注意事项:
- 内存限制:代码缓存区有固定的最大值(可通过
-XX:ReservedCodeCacheSize参数配置),需要注意在长时间运行的应用程序中这个区不会被耗尽,否则可能导致性能退化。 - 清理与优化:JVM 在启动时和运行过程中可能会执行代码缓存的清理和优化,这个过程会对性能有一定影响。
# 2. Compressed Class Space(压缩类空间)
用途:
- 存储类元数据:在开启类指针压缩的情况下(默认开启),这个空间用于存储类元数据的压缩指针,以节省内存空间。
- 支持元空间:压缩类空间是元空间的一部分,专门用来优化类加载器的内存消耗。
注意事项:
- 有固定最大限制:虽然是元空间的一部分,但压缩类空间有自己的最大内存限制(默认为 1GB),可以通过
-XX:CompressedClassSpaceSize参数调整。 - 适配性告诉:32 位 JVM 不使用压缩类空间功能,64 位 JVM 在默认情况下是开启的,因其节省的内存对大型应用尤其重要。
# 3. Metaspace(元空间)
用途:
- 替换永久代:Java 8 开始,用元空间替代了永久代,用于存储类的元数据(类的结构信息、方法、字段等)。
- 动态调整大小:与永久代不同,元空间作为物理内存的一部分,不断增长(直到达到物理内存上限),默认不设置上限,灵活性更高。
注意事项:
- 内存泄漏风险:尽管更灵活,但如果不加限制,糟糕的类加载策略可能导致元空间内存泄漏。在开发环境中尤其要防止过度类加载。
- 调整与监控:可以通过
-XX:MetaspaceSize和-XX:MaxMetaspaceSize进行调节,适当限制,在实际使用中密切监控。 - 自动释放:JVM 在内存不足时会尝试回收未使用的类加载的内存,虽然一般无需手动干预,了解这方面的配置有助于优化内存使用。
这些部分的配置和监控是调优 JVM 的重要组成部分,适当的配置可以防止内存泄漏、排查性能瓶颈,并为应用程序的稳定性提供保障。
# 4.2 火焰图
# 4.2.1 生成脚本
profiler 命令支持生成应用热点的火焰图。本质上是通过不断的采样,然后把收集到的采样结果生成火焰图。火焰图可以清楚的看到程序运行中对象的创建,这样你就可以发现那些大对虾(像)从哪来的?
操作过程,开启采集 profiler start --event alloc 等待程序执行,关闭采集 profiler stop --format html
我们操作中,开启采集后,可以先执行多次的 curl-one.sh 调用接口,多产生点对象。
profiler start --event alloc
profiler getSamples
profiler status
profiler stop --format html
2
3
4
5
6
7
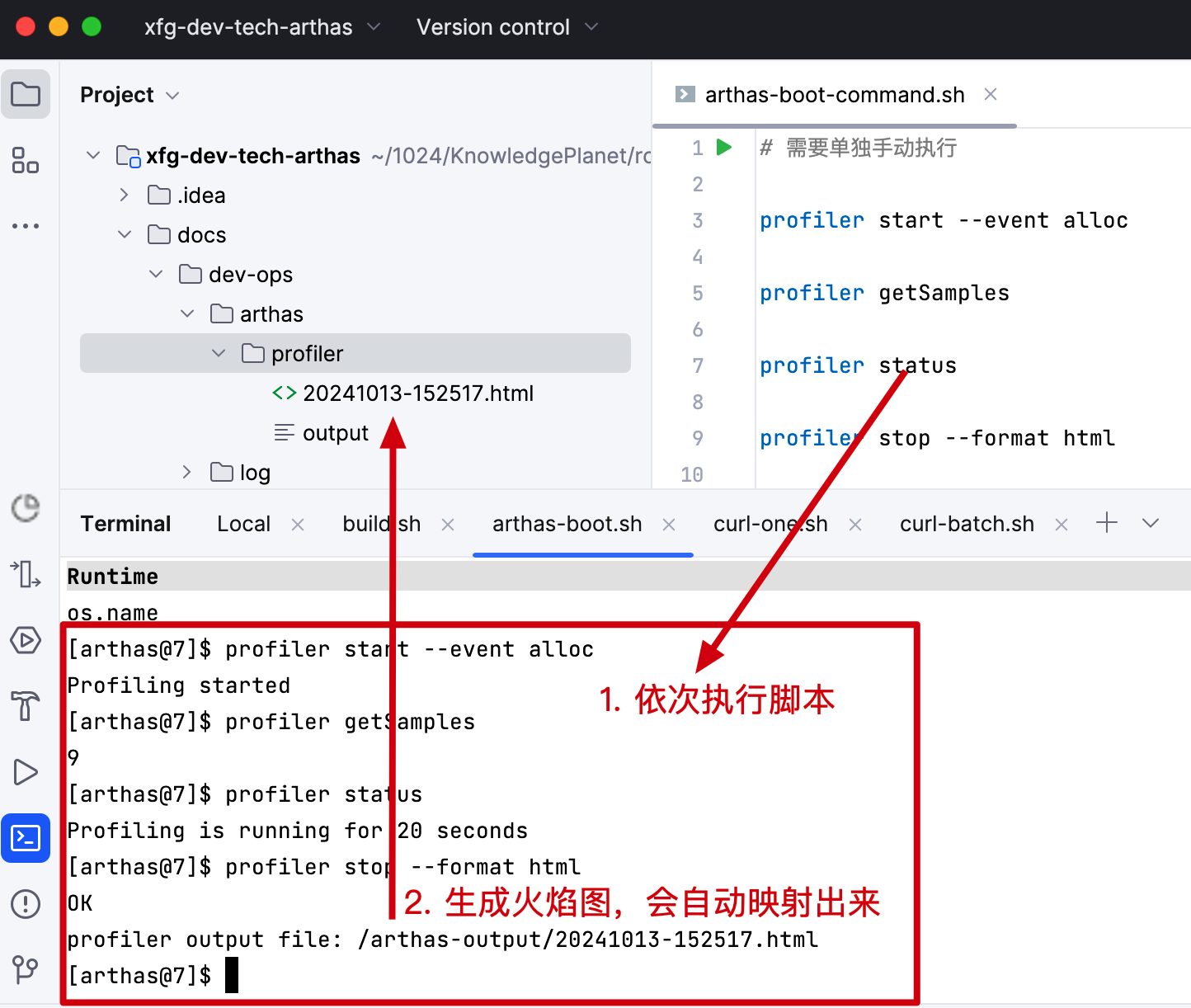
- 执行完成后,你会得到一个火焰图的 html 文件。之后就可以打开了。
# 4.2.2 查看图表
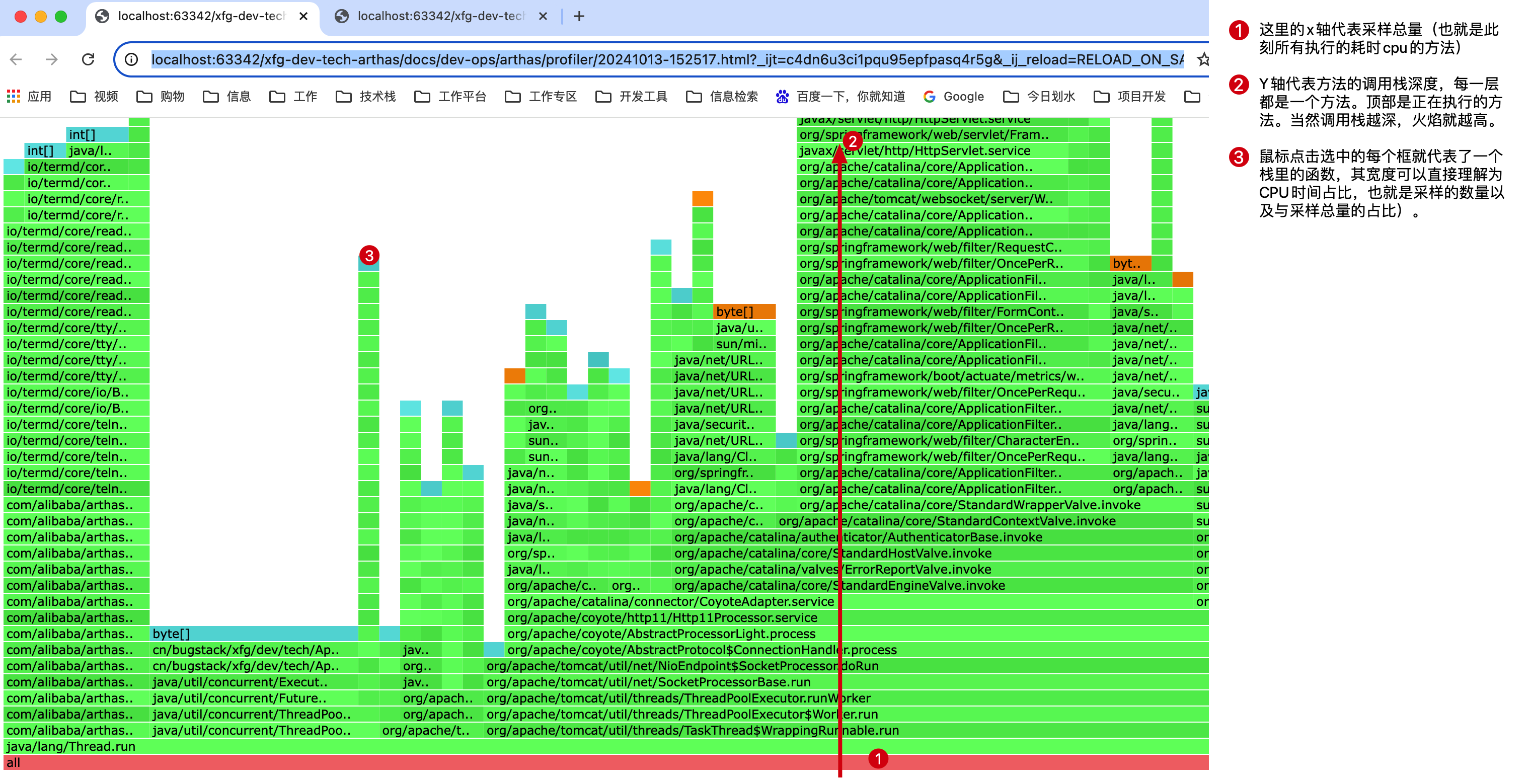
- 这里的x轴代表采样总量(也就是此刻所有执行的耗时cpu的方法)。这是注意的是x 轴并不代表时间,而是所有的调用方法合并后,按字母顺序排列。
- Y轴代表方法的调用栈深度,每一层都是一个方法。顶部是正在执行的方法。当然调用栈越深,火焰就越高。
- 鼠标可以点击的选中的每个框就代表了一个栈里的函数,其宽度可以直接理解为CPU时间占比(其实是采样的数量以及与采样总量的占比)。
- 那么,也就是说占比比较宽的框就表示:a.该函数运行时间较长(单次时间长)b.被调用次数较多.(调用频率高)进而被采样的次数比较多,占用的CPU时间多。
- 这样你就知道了是哪里在创建大对像。比如一些数据库对象,缓存对象等,特别大,又耗时,一下就监控出来了。
Arthas 提供的功能还有很多,不过咱们要换个更加舒服的方式使用了。如下。
# 五、IDEA Plugin Arthas
# 1. 安装插件

# 2. 使用插件
这些命令你都可以通过 Arthas IDEA Plugin 插件复制出来使用。
- monitor (opens new window) - 方法执行监控
- stack (opens new window) - 输出当前方法被调用的调用路径
- trace (opens new window) - 方法内部调用路径,并输出方法路径上的每个节点上耗时
- tt (opens new window) - 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
- watch (opens new window) - 方法执行数据观测
更多命令 https://arthas.aliyun.com/doc/commands.html (opens new window)
# 2.1 复制命令
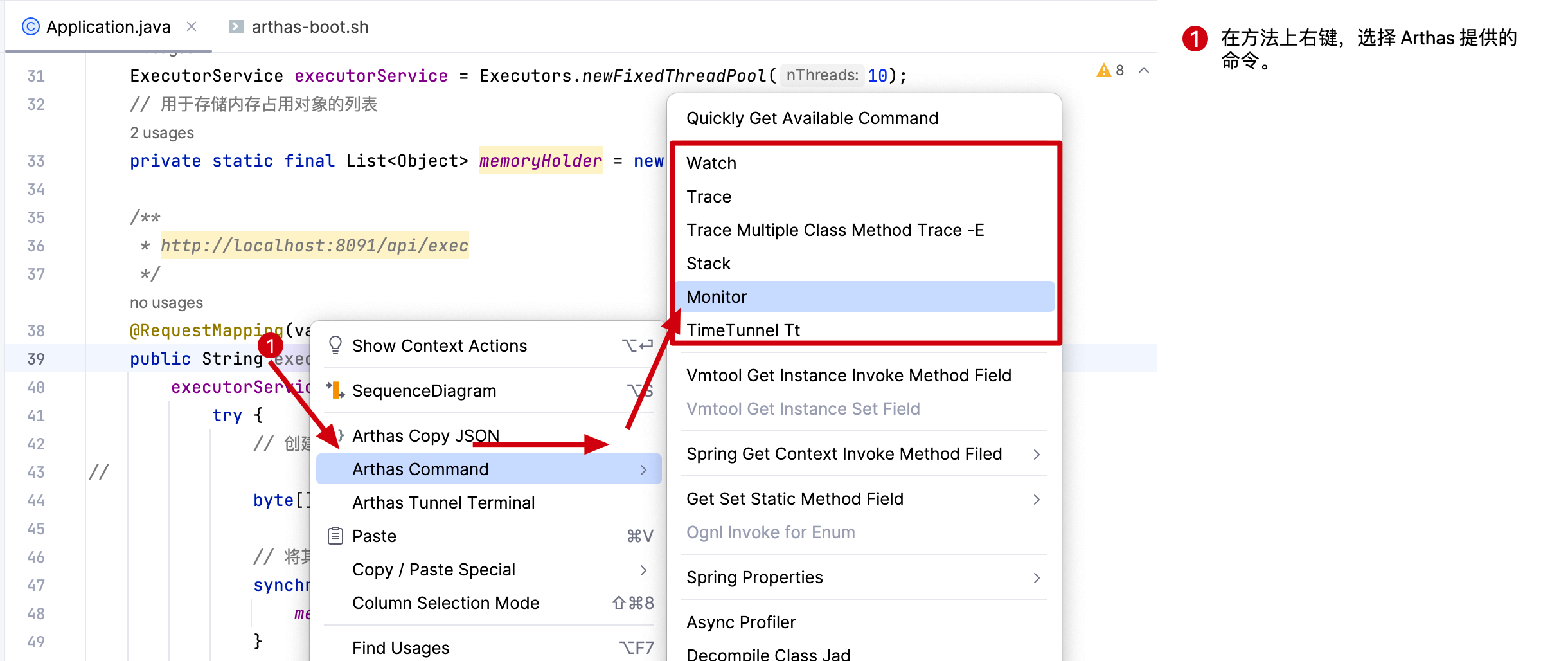
# 2.2 使用命令
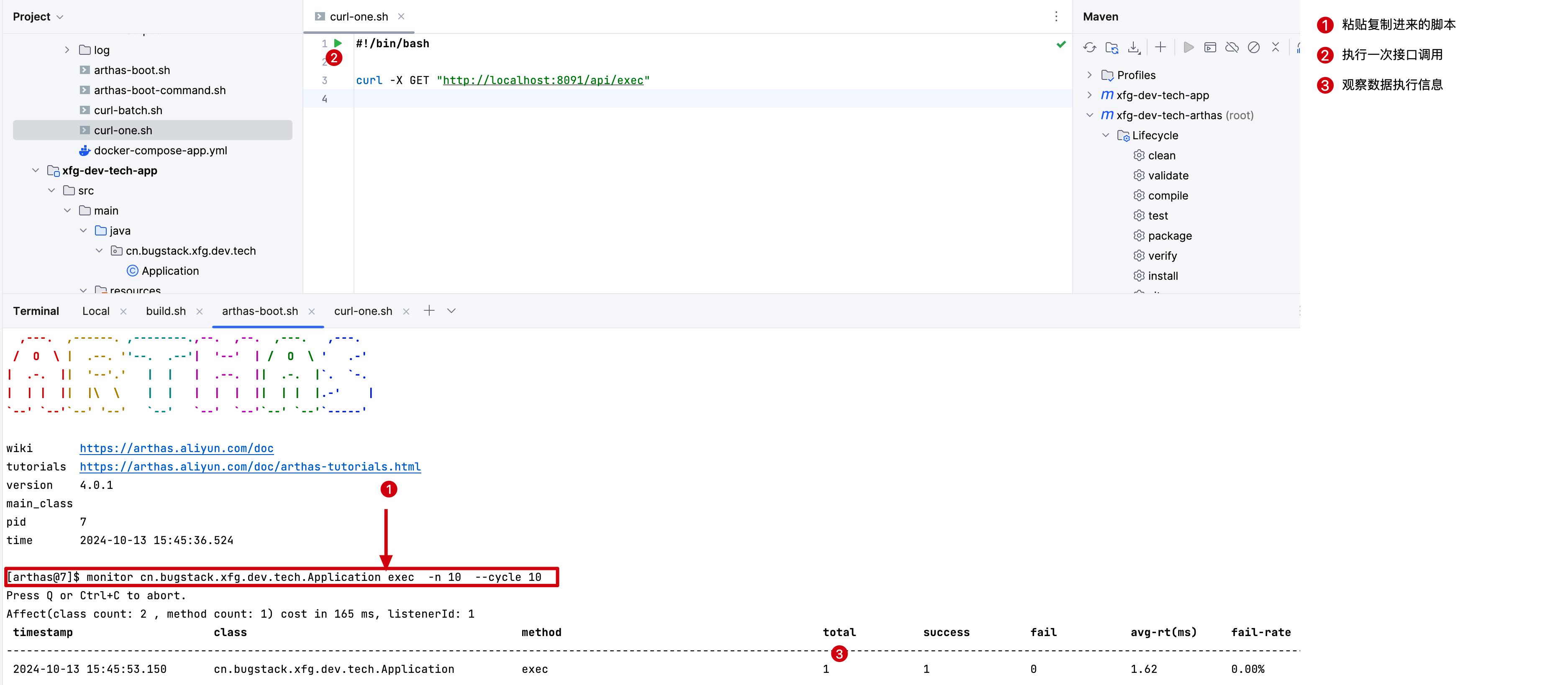
- 如图你就可以监控到方法的运行信息了。
# 3. 其他命令
# 3.1 查看代码
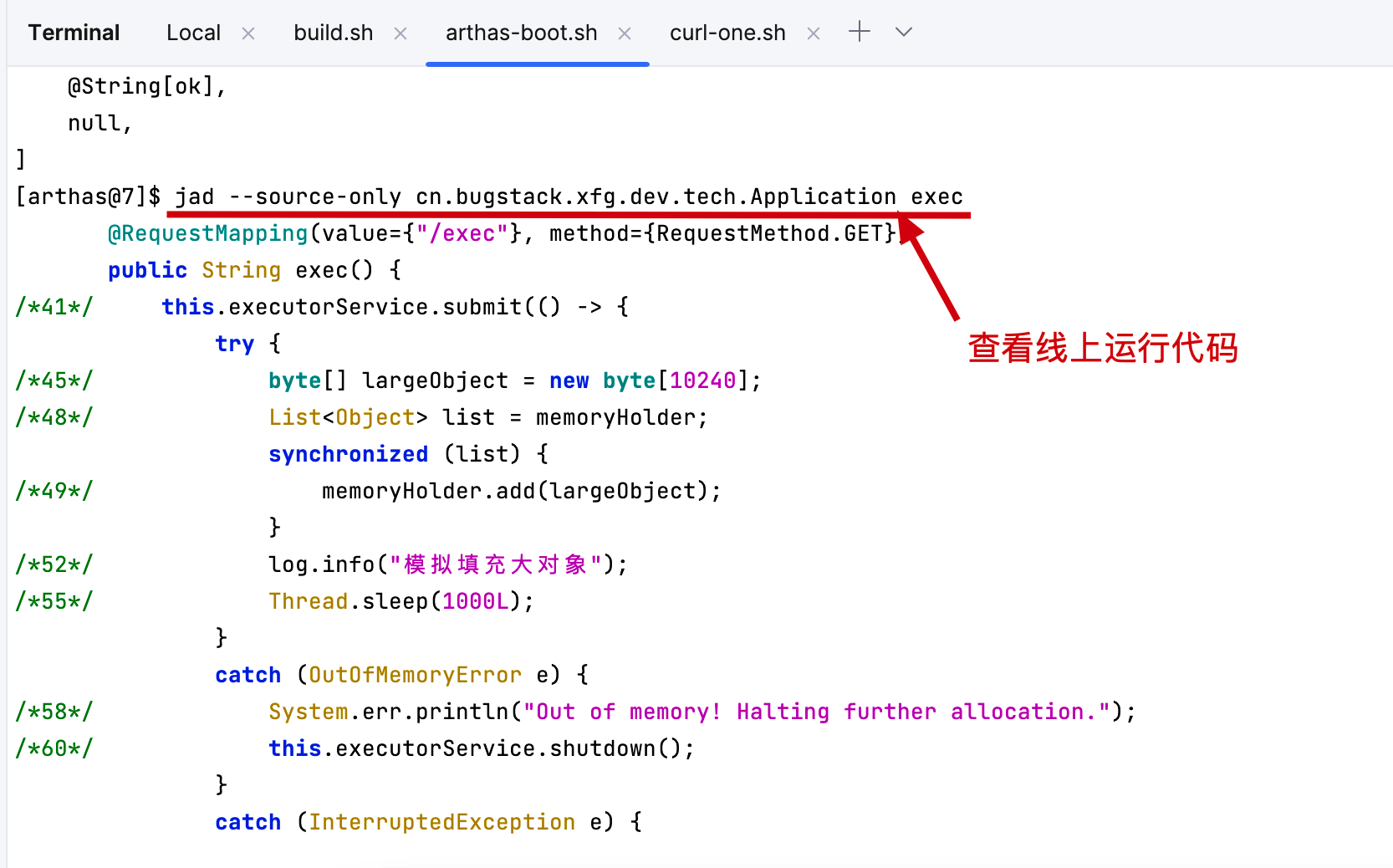
- 线上运行的代码,不确定是否是最新的,那么这样就可以一步获取到并对比。
# 3.2 接口参数

- 有时候预发验证服务,因为不会打印所有的服务接口出入参信息,但遇到问题不好排查。
- 那么使用 Arthas 插件,就可以直接获取到接口的出入参了,方便排查问题。
其他更多命令可以通过官网的命令提示和插件一起使用验证了。

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.