# 数据结构:字典树 Trie
作者:小傅哥
博客:https://bugstack.cn (opens new window)
原文:https://mp.weixin.qq.com/s/4scA6vlno0TzBZWQrCXI_w (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
# 一、前言
Trie 的历史
字典树 Trie 这个词来自于 retrieval,于 1912 年,Axel Thue 首次抽象地描述了一组字符串数据结构的存放方式为 Trie 的想法。这个想法于 1960 年由 Edward Fredkin 独立描述,并创造了 Trie 一词。你看看,多少程序员为了一个词、方法名、属性名,想破脑袋!
# 二、字典树数据结构
在计算机科学中,字典树(Trie)也被称为”单词查找树“或”数字树“,有时候也被称为基数树或前缀树(因为可以通过前缀的方式进行索引)。—— 它是一种搜索树,一种已排序的数据结构,通常用于存储动态集或键为字符串的关联数组。
与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。

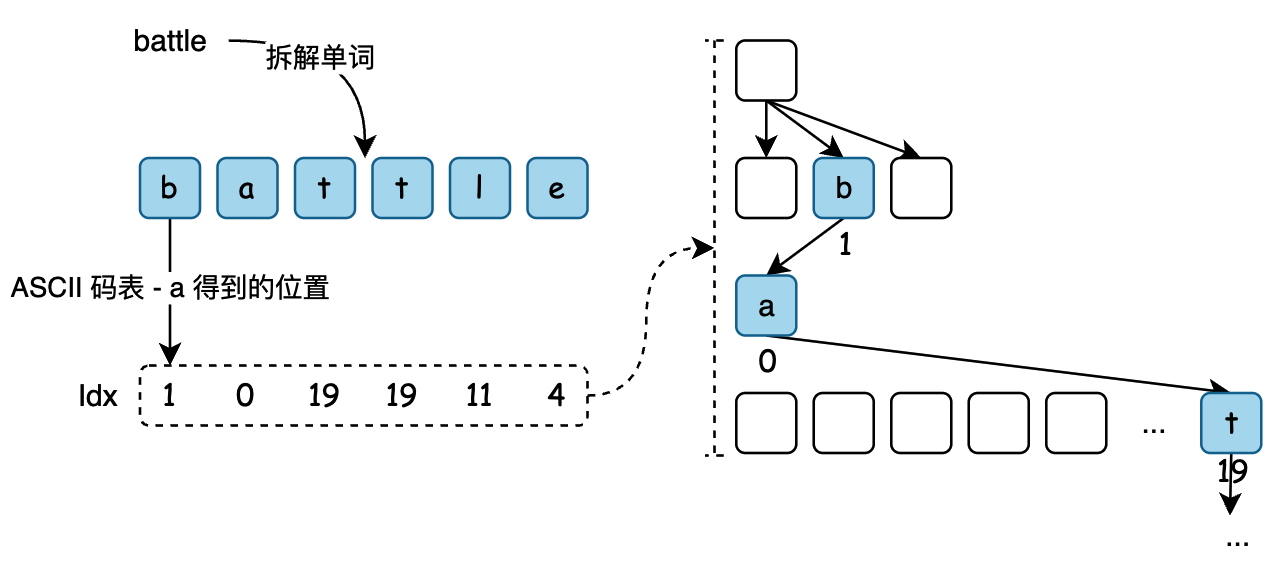
- 这是一个把 battle 单词字符串,按照字母拆分到字典树进行存放的图。
- 键标注在节点中,值标注在节点之下。每一个完整的英文单词对应一个特定的整数。也就是26个字母对应的 ASCII 转换后的值。
# 三、字典树结构实现
字典树字母的存放有26个,也就是说在实现的过程中,每一个节点的分支都有26个槽位用来存放可能出现的字母组合。同理如果是数字树的话就是10个数字的组合,每个字典树上的节点对应的分支则有10个操作存放可能出现组合的数字。
接下来我们就基于 Java 语言实现一个字典树的存放和遍历索引的功能。
- 源码地址:https://github.com/fuzhengwei/java-algorithms (opens new window)
- 本章源码:https://github.com/fuzhengwei/java-algorithms/tree/main/data-structures/src/main/java/trie (opens new window)
# 1. 树枝节点
public class TrieNode {
/** 形成一个链 */
public TrieNode[] slot = new TrieNode[26];
/** 字母 */
public char c;
/** 单词:数量 > 0 表示一个单词 */
public boolean isWord;
/** 前缀 */
public int prefix;
/** 单词:具体的一个单词字符串 */
public String word;
/** 解释:单词的注释说明 */
public String explain;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 字典的树的节点需要包括此节点内嵌的关联节点,之后是节点的字母、到此字母是否为单词、单词的前缀、单词字符串和当前单词的非必要注释。
# 2. 插入元素
public void insert(String words, String explain) {
TrieNode root = wordsTree;
char[] chars = words.toCharArray();
for (char c : chars) {
int idx = c - 'a'; // - a 从 0 开始,参考 ASCII 码表
if (root.slot[idx] == null) {
root.slot[idx] = new TrieNode();
}
root = root.slot[idx];
root.c = c;
root.prefix++;
}
root.explain = explain; // 单词的注释说明信息
root.isWord = true; // 循环拆解单词后标记
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- insert 方法接收单词和注释信息,并对一个单词按照 char 进行拆分,拆分后则计算出索引位置并以此存放。存放完成后标记单词和附属上单词的注释信息。
# 3. 索引元素
public List<String> searchPrefix(String prefix) {
TrieNode root = wordsTree;
char[] chars = prefix.toCharArray();
StringBuilder cache = new StringBuilder();
// 精准匹配:根据前置精准查找
for (char c : chars) {
int idx = c - 'a';
// 匹配为空
if (idx > root.slot.length || idx < 0 || root.slot[idx] == null) {
return Collections.emptyList();
}
cache.append(c);
root = root.slot[idx];
}
// 模糊匹配:根据前缀的最后一个单词,递归遍历所有的单词
ArrayList<String> list = new ArrayList<>();
if (root.prefix != 0) {
for (int i = 0; i < root.slot.length; i++) {
if (root.slot[i] != null) {
char c = (char) (i + 'a');
collect(root.slot[i], String.valueOf(cache) + c, list, 15);
if (list.size() >= 15) {
return list;
}
}
}
}
return list;
}
protected void collect(TrieNode trieNode, String pre, List<String> queue, int resultLimit) {
// 找到单词
if (trieNode.isWord) {
trieNode.word = pre;
// 保存检索到的单词到 queue
queue.add(trieNode.word + " -> " + trieNode.explain);
if (queue.size() >= resultLimit) {
return;
}
}
// 递归调用,查找单词
for (int i = 0; i < trieNode.slot.length; i++) {
char c = (char) ('a' + i);
if (trieNode.slot[i] != null) {
collect(trieNode.slot[i], pre + c, queue, resultLimit);
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
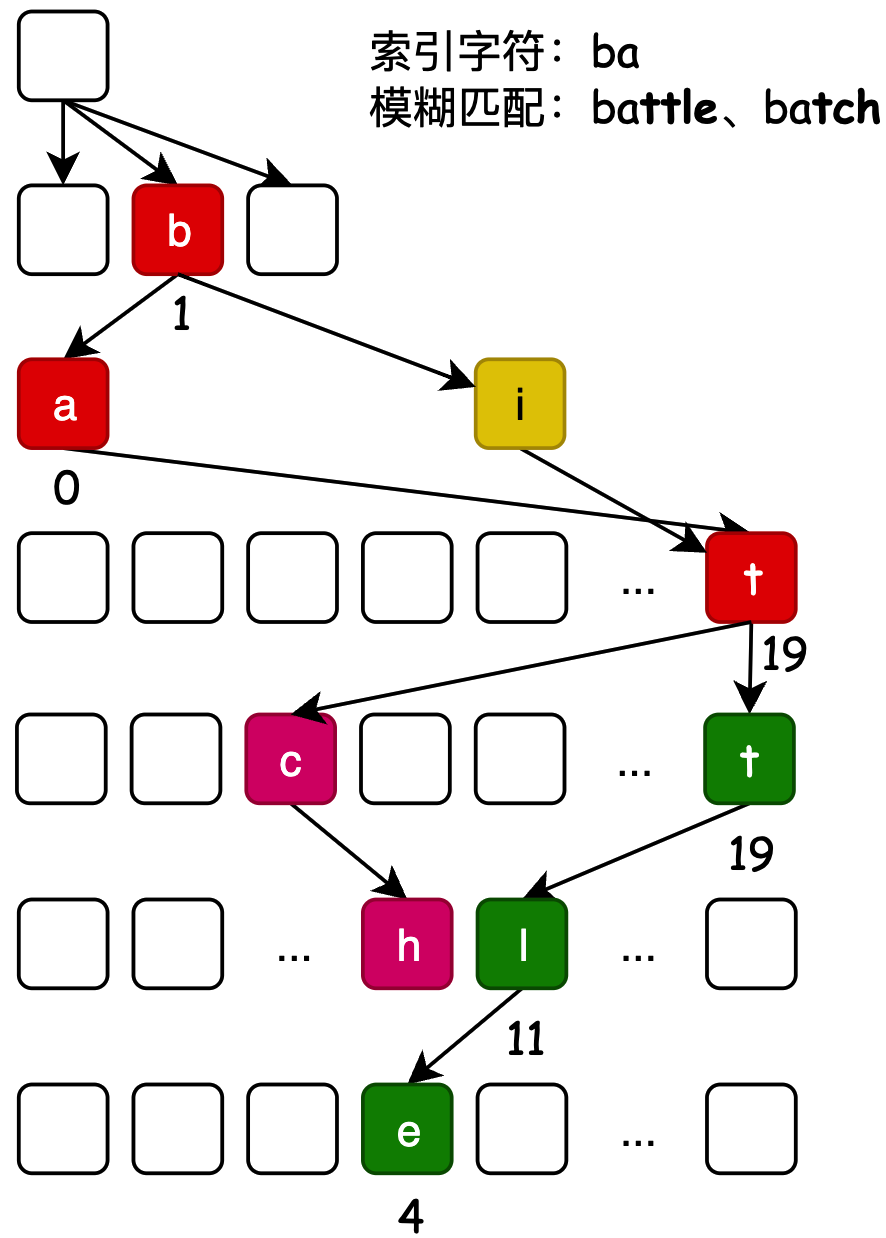
- 从字典树从检索元素的过程分为2部分,第1部分是根据提供的索引前缀精准匹配到单词信息,第2部分是根据索引前缀的最后一个单词开始,循环递归遍历从当前位置所能关联到的字母直至判断为是单词标记为结束,通过这样的方式把所有匹配动的单词索引出来。
- list.size() >= 15 是判定索引的最大长度,超过这个数量就停止索引了,毕竟这是一种O(n)时间复杂度的操作,如果加载数十万单词进行匹配,执行速度还是比较耗时的。
# 四、字典树功能测试
@Test
public void test_trie() {
Trie trie = new Trie();
// 存入
trie.insert("bat","大厂");
trie.insert("batch", "批量");
trie.insert("bitch", "彪子");
trie.insert("battle", "战斗");
logger.info(trie.toString());
// 检索
List<String> trieNodes = trie.searchPrefix("ba");
logger.info("测试结果:{}", JSON.toJSONString(trieNodes));
}
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
- 这里提供一些有相近字母的单词和名词,用于测试。你也可以尝试读取txt文件,检索存入数十万单词进行检索验证。
测试结果
06:21:38.226 [main] INFO trie.__test__.TrieTest - 测试结果:["bat -> 大厂","batch -> 批量","battle -> 战斗"]
Process finished with exit code 0
1
2
3
2
3
- 通过测试结果可以看到,把所有以 ba 开头的单词全部检索出来了。这也是字典树最核心功能的体现。
- 读者在学习的过程中,可以尝试在检索的方法体内打一些断点看一下具体的执行过程,方便学习整个执行步骤。
# 五、常见面试题
- 简述字典树的数据结构
- 叙述你怎么来实现一个字典树
- 字典树的实际业务场景举例【排序、全文搜索、网络搜索引擎、生物信息】
- 字典树的存入和检索的时间复杂度
- 还有哪些字典树的实现方式【后缀树 (opens new window)、哈希树 (opens new window)、帽子树 (opens new window)】
京ICP备19031103号 | 
京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.