# 《大营销平台系统设计实现》 - 营销服务 第31节:分库分表数据同步ES
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
- 本章难度:★★★☆☆
- 本章重点:为分库分表搭建 canal 数据同步 ElasticSearch 文件操作。
- 课程视频:https://t.zsxq.com/5O0SI (opens new window)
版权说明:©本项目与星球签约合作,受《中华人民共和国著作权法实施条例》 (opens new window) 版权法保护,禁止任何理由和任何方式公开(public)源码、资料、视频等内容到Github、Gitee等,违反可追究进一步的法律行动。
# 一、本章诉求
对于C端的场景来说,我们经常会采用分库分表的方案承载数据流量的压力,以用户ID为切分键,让用户的行为数据分散到各个库表中。那么在C端除了给用户提供数据服务以外,还需要给运营提供数据,但分库分表后的数据都已经散列到各个库表了,对于聚合查询就变得复杂,所以我们还需要另外一套方案。就是把分散在各个数据库表的数据,通过使用 canal 组件,基于 binlog 日志,把数据同步到 ElasticSearch 文件服务中再提供使用。
# 二、组件介绍
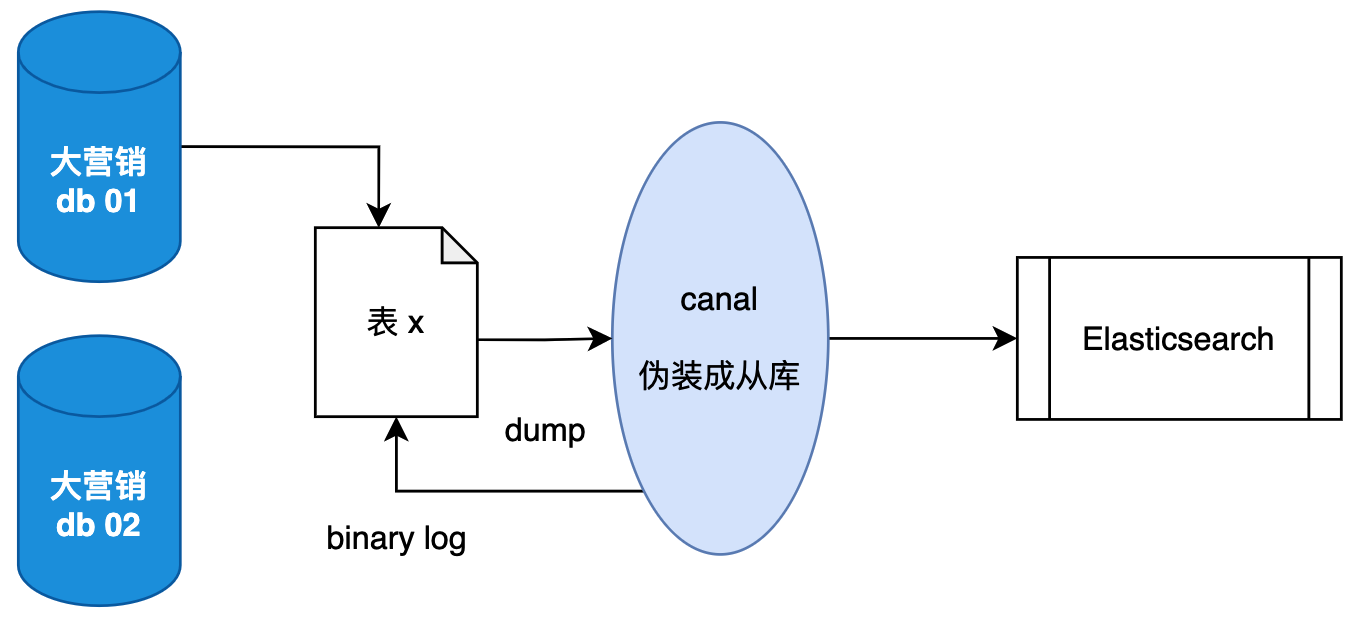
canal ,译为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
它的工作原理是,canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。在 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) 这样 canal 再解析 binary log (binlog)进行配置分发,同步到 Elasticsearch 等系统中进行使用。
那么有了 canal 就可以把分库分表的数据同步到 Elasticsearch,提供汇总查询和聚合操作,也就不需要把轮训每个分库分表数据了。

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.